Einen Serverlosen KI-Barkeeper aufbauen - Teil 3: Der KI-Chat-Agent

Diese Datei wurde automatisch von KI ubersetzt, es konnen Fehler auftreten
In Teil 1 habe ich das Fundament mit Aurora DSQL, APIs und ereignisgesteuerten Workflows aufgebaut. In Teil 2 habe ich Gästeanmeldung und Live-Bestellupdates mit AppSync Events hinzugefügt. Gäste können Getränke durchsuchen und Bestellungen aufgeben. Aber es ist immer noch nur eine digitale Speisekarte.
Hier kommt die KI ins Spiel. Der Hauptpunkt dieses kleinen Projekts war, dass ich nicht die Speisekarte sein sollte. Ich wollte eine digitale Speisekarte, aber auch einen KI-Cocktail-Assistenten, der Getränke empfehlen kann, anstatt ich selbst es zu tun. Ich musste etwas bauen, das Vorlieben versteht, Getränke empfiehlt, aber nur Getränke vorschlägt, die ich tatsächlich mixen kann.
Dieser letzte Teil brachte mehrere Herausforderungen mit sich; ich brauchte ein paar zusätzliche Tage, um die Dinge so zu bekommen, wie ich es wollte. Beim ersten Test des Chatbots empfahl er einen "Mojito", aber ich hatte "Mojito" nicht auf der Speisekarte. Die KI schlug gute Getränke vor, prüfte aber nicht, ob es möglich war, sie zu mixen. Ich lernte, dass der Aufbau von KI-Agenten nicht nur darin besteht, eine Sprachmodelle anzuschließen. Es geht darum, zu kontrollieren, was das Modell sagen kann und was nicht.
Der vollständige Quellcode für dieses Projekt ist auf GitHub verfügbar.
Lass uns den KI-Barkeeper bauen.
Der Barkeeper in Aktion
Bevor wir in die technischen Details eintauchen, lass mich dir zeigen, was wir bauen. Dies ist die tatsächliche Chat-Schnittstelle, die Gäste nutzen können.
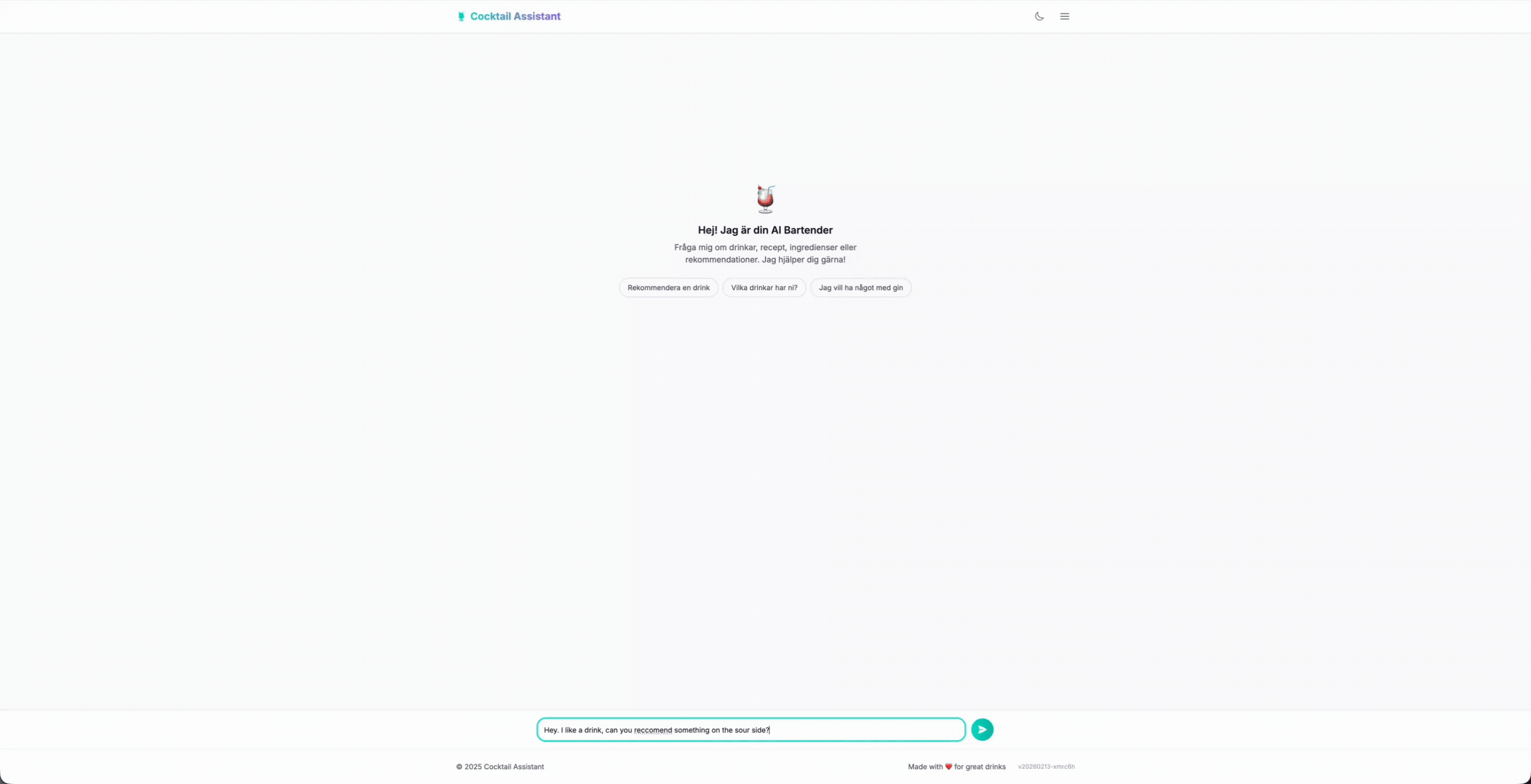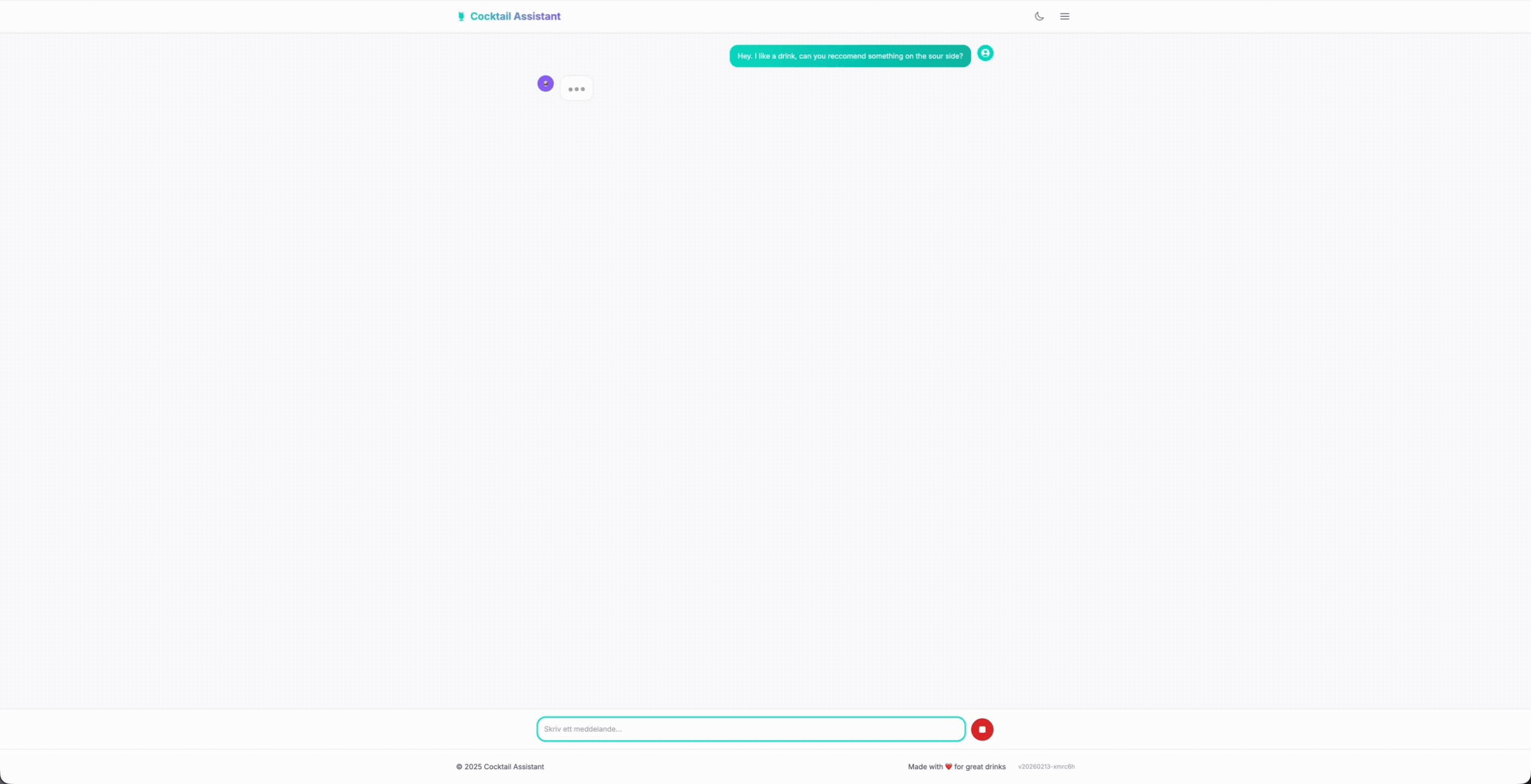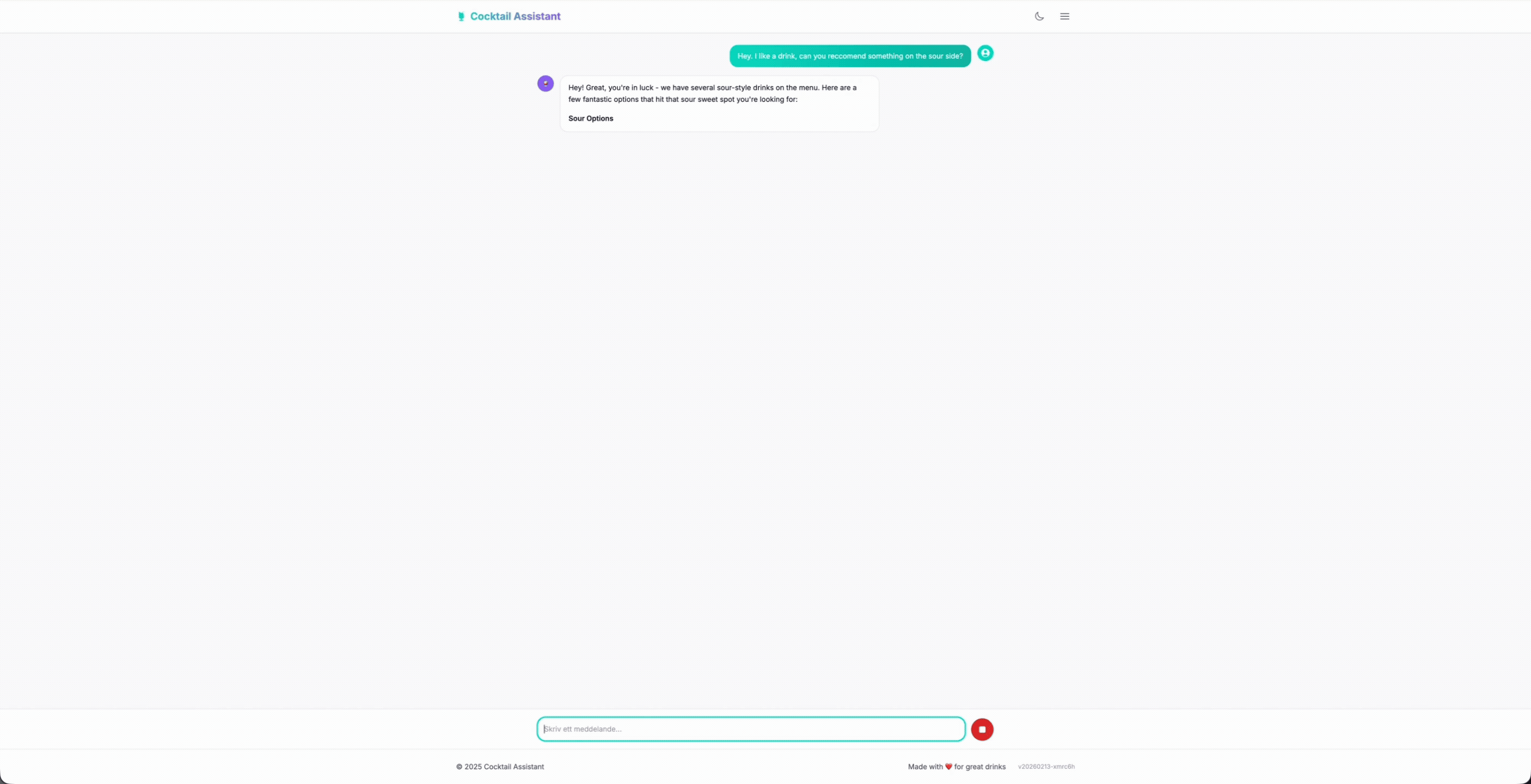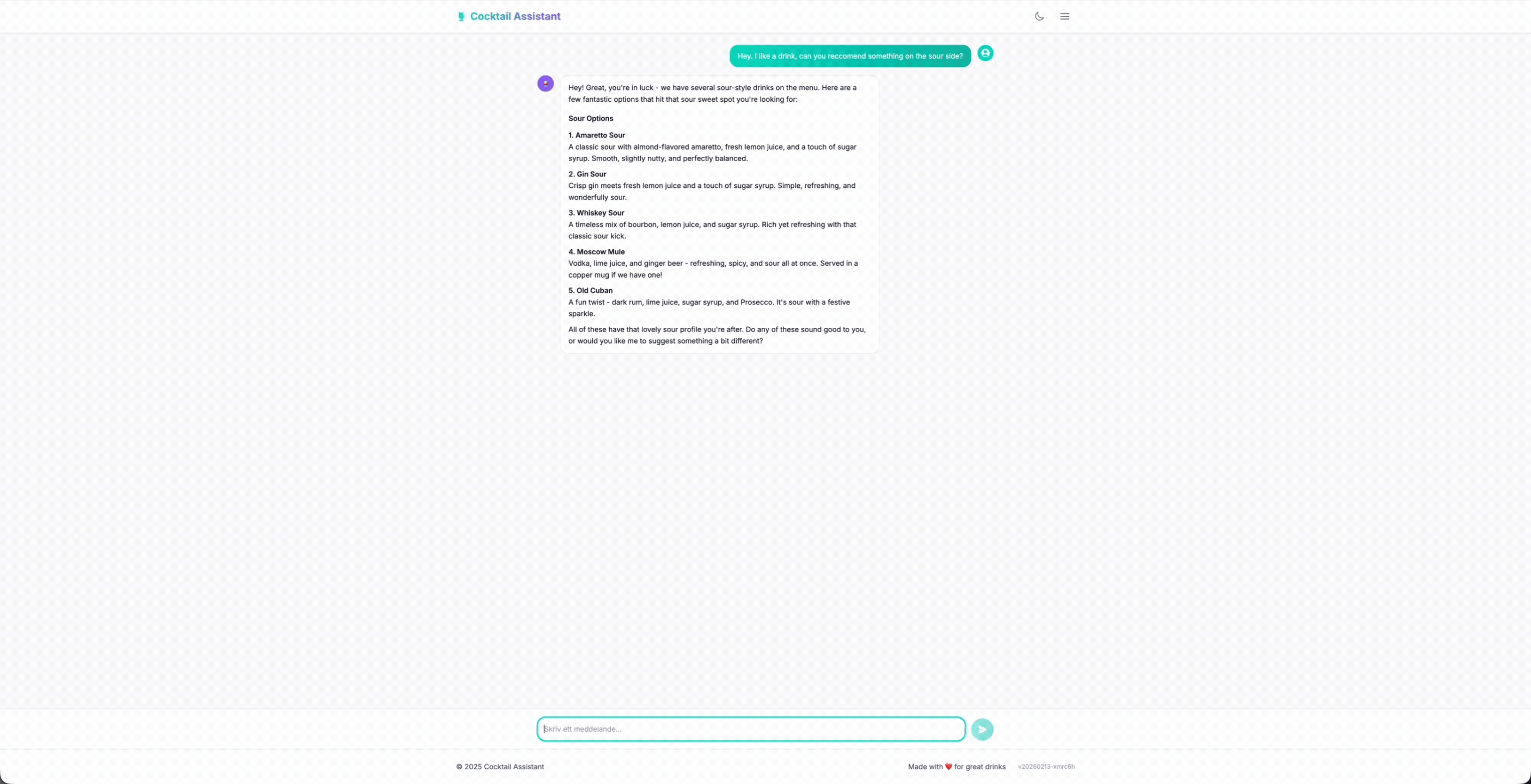
Der Gesprächsfluss verläuft natürlich; der Benutzer fragt nach Getränken, fügt seine Vorlieben wie süß, sauer, bitter usw. hinzu. Der Barkeeper hakt nach, ruft die Speisekarte ab und empfiehlt Getränke, die tatsächlich existieren. Wenn jemand nach etwas fragt, das wir nicht haben, leitet er höflich um, anstatt sich Dinge auszudenken.
Was du nicht siehst, ist alles, was hinter dieser Schnittstelle passiert. Der Agent ruft meine MCP-Tools auf, um die Speisekarte abzurufen, lädt den Gesprächsverlauf aus AgentCore Memory, streamt die Antwort Wort für Wort über Lambda Web Adapter und folgt strengen Regeln, um Halluzinationen zu verhindern. Alles unsichtbar für den Gast. Alles macht die Erfahrung so, als würde man mit einem echten Barkeeper sprechen.
Architekturüberblick
Lass uns einen Blick auf die Architektur und die Dienste werfen, die wir nutzen werden, um den KI-Barkeeper-Chatbot zu bauen.
Ich habe das Frontend in React, das AWS Api Gateway aufruft; dies wird mit Streaming-Antwort erstellt und eingerichtet. Um die Logik zu implementieren, greife ich natürlich auf Lambda zurück, das als Integration mit der API eingerichtet ist. Um die agentische Schleife auf einfache Weise zu handhaben, kommen Strands Agents zur Rettung. Unsere Lambda-Funktion, mit Strands, interagiert dann mit Amazon Bedrock und verwendet Amazon Nova 2 Lite als LLM. Amazon AgentCore bietet einige sehr wichtige Teile: Speicher, um das Gespräch zu führen, und Gateway, um meine MCP-Tools zu erreichen. Dies schafft eine stabile, kostengünstige und serverlose Lösung!

Streaming-Chat-API
Das Erste, was ich brauchte, war einen API-Endpunkt für den Chat zu erstellen. Wir haben bereits ein API Gateway von Teil 1 und 2, das alle REST-Endpunkte abhandelt: Durchsuchen von Getränken, Verwalten der Speisekarte, Aufgeben von Bestellungen. Mein erster Instinkt war, diese API zu erweitern und dort eine /chat-Route hinzuzufügen. Das funktionierte nicht wirklich so, wie ich es wollte.
Die Haupt-API verwendet die Events-Eigenschaft von SAM für Lambda-Funktionen, um Endpunkte zu definieren. So richte ich es normalerweise ein, auch wenn es ein paar Fehler hat. Es ist einfach zu einfach für Standardanfragen-Antwort-Muster, nicht dafür. Aber ich brauchte Antwort-Streaming für den Chat, und SAM Events unterstützen derzeit nicht responseTransferMode. Es gab einfach keine Möglichkeit, es auf die normale Weise zu konfigurieren.
Um dies zu ermöglichen, musste ich eine OpenAPI-Spezifikation verwenden und responseTransferMode auf STREAM setzen, da es nicht möglich war, die aktuelle API beizubehalten und nur die OpenAPI-Spezifikation für den neuen Endpunkt hinzuzufügen; die Lösung wurde ein neuer dedizierter Stack für die Chat-API. Also habe ich eine separate AWS::Serverless::Api mit einem OpenAPI DefinitionBody erstellt. Ein Vorteil, der damit einhergeht, ist, dass ich die APIs entkoppeln kann; ich kann die REST-basierte Speisekarten-API und die KI-Chat-API separat bereitstellen. Chat-Änderungen riskieren nicht, den Bestellablauf zu stören, und umgekehrt.
paths:
/chat:
post:
x-amazon-apigateway-integration:
type: aws_proxy
httpMethod: POST
responseTransferMode: "STREAM"
uri:
Fn::Sub: >-
arn:aws:apigateway:${AWS::Region}:lambda:path/2021-11-15/functions/${ChatStreamingFunction.Arn}/response-streaming-invocationsErstens sagt responseTransferMode: "STREAM" dem API Gateway, die Antwort zu streamen, anstatt sie zu puffern. Zweitens verwendet der URI-Pfad /response-streaming-invocations anstelle des normalen /invocations. Dies ist eine andere Lambda-Aufruf-API, die Chunked Transfer unterstützt. Ohne beide würde API Gateway die vollständige Lambda-Antwort abwarten, bevor es etwas an den Client sendet.
Antwort-Streaming
Warum all diese Mühe auf sich nehmen und all diese Hürden überwinden, nur für Streaming? Weil der Unterschied im Benutzererlebnis riesig ist.
Die erste Version, die ich vom Chat gebaut habe, war synchron; es war einfach einfacher so. Die Lambda wartete auf die vollständige Antwort von Bedrock und gab dann alles auf einmal zurück. Aber es floss nicht natürlich; heutzutage sind alle an Antworten gewöhnt, die in Streams kommen. ChatGPT, Claude, Gemini und praktisch alle KI-Chats sind so aufgebaut.
Mit Streaming sieht der Benutzer das erste Wort in Millisekunden, anstatt Sekunden auf die vollständige Antwort zu warten. Der Rest fließt Wort für Wort; am Ende ist die Gesamtzeit etwa gleich, aber es fühlt sich so viel flüssiger an, und als Menschen erleben wir es als natürlicher.
Der technische Begriff dafür ist "Zeit bis zum ersten Token" im Gegensatz zu "Zeit bis zum letzten Token". Für gepufferte Antworten sind beide gleich. Beim Streaming beträgt die Zeit bis zum ersten Token typischerweise weniger als eine Sekunde. Dieses erste Token ist es, was zählt!
Es gibt auch einen praktischen Vorteil. Wenn das Modell anfängt, Unsinn zu generieren oder in einer Schleife stecken bleibt, sieht der Benutzer es sofort und kann abbrechen.
Lambda Web Adapter für Python-Streaming
Nun gibt es hier einen Haken. Python Lambda unterstützt Antwort-Streaming nicht nativ. Nur Node.js hat eine eingebaute Streaming-Unterstützung über die Streaming-API von Lambda. Aber ich wollte den Agenten in Python bauen, weil Python meine bevorzugte Sprache ist und da alles andere im Backend Python-basiert ist, wollte ich versuchen, es so zu belassen.
Die Lösung hier ist die Verwendung von Lambda Web Adapter. Es ist ein von AWS veröffentlichter Lambda-Layer, der dein Web-Framework – in meinem Fall FastAPI – umhüllt und zwischen Lambdas Streaming-Aufruf-API und Standard-HTTP-Antworten übersetzt. Du schreibst eine normale FastAPI-App mit StreamingResponse, und der Adapter kümmert sich um den Rest.
ChatStreamingFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/chat-streaming/
Handler: run.sh
Runtime: python3.13
Architectures:
- arm64
Timeout: 120
MemorySize: 1024
Layers:
# Lambda Web Adapter layer published by AWS
- !Sub arn:aws:lambda:${AWS::Region}:753240598075:layer:LambdaAdapterLayerArm64:25
Environment:
Variables:
AWS_LAMBDA_EXEC_WRAPPER: /opt/bootstrap
PORT: 8080
AWS_LWA_INVOKE_MODE: RESPONSE_STREAMEs gibt drei Umgebungsvariablen, die dies am Ende zum Laufen bringen. AWS_LAMBDA_EXEC_WRAPPER sagt Lambda, den Adapter als Einstiegspunkt zu verwenden, anstatt deinen Handler direkt aufzurufen. PORT sagt dem Adapter, an welchem Ort deine FastAPI-App hört. Und AWS_LWA_INVOKE_MODE auf RESPONSE_STREAM aktiviert die Chunked Transfer-Kodierung, die Streaming ermöglicht.
Der Lambda-Handler ist nur ein kleines zweizeiliges Shell-Skript, das den FastAPI-Server startet.
#!/bin/bash
exec python handler.pyDer Adapter fängt die Anfragen von Lambdas Streaming-API ab, leitet sie über HTTP an FastAPI auf Port 8080 weiter und streamt die Antwort dann Stück für Stück zurück. Aus der Perspektive meines Codes schreibe ich einfach eine normale FastAPI-App. Der Streaming-Teil wird vollständig von der Layer übernommen.
Am Ende wird dies also zu einer ziemlich flüssigen Lösung. Du kannst die Lösung auch auf Serverless Land finden.
Im Inneren der Chat-Lambda
Nachdem die API und das Streaming eingerichtet sind, lass uns einen Blick darauf werfen, was tatsächlich in der Lambda-Funktion läuft.
Strands Agents
Wenn wir einen KI-Agenten von Grund auf bauen, müssen wir viel implementieren: die Nachricht des Benutzers an das Modell senden, überprüfen, ob das Modell einen unserer Tools aufrufen möchte, das Tool aufrufen, das Ergebnis zurück an die LLM senden, erneut überprüfen und weiterlaufen, bis das Modell eine endgültige Antwort hat. Grundsätzlich müssen wir das implementieren, was oft als agentische Schleife bezeichnet wird. Dann kommt Streaming, Fehlerwiederherstellung und Gesprächszustand dazu.
Strands Agents ist ein Open-Source-SDK von AWS, das uns hilft, die agentische Schleife zu implementieren. Es hilft uns, die Implementierungszeit von Wochen auf Tage zu reduzieren. Es wird die agentische Schleife für uns ausführen. Wenn das Modell entscheidet, dass es die Speisekarte überprüfen muss, ruft Strands den Tool-Aufruf auf, gibt das Ergebnis zurück und fährt fort, bis das Modell zufrieden ist und eine vollständige Antwort hat. Es integriert sich auch direkt in AgentCore Memory für die Sitzungsverwaltung und unterstützt asynchrones Streaming.
Die grundlegende Einrichtung ist überraschend einfach.
from strands import Agent
from strands.models.bedrock import BedrockModel
model = BedrockModel(model_id="amazon.nova-2-lite-v1:0")
agent = Agent(model=model, system_prompt="You are a bartender.")
for chunk in agent.stream("Suggest a gin drink"):
print(chunk, end="")Drei Zeilen und du hast einen Streaming-KI-Agenten. Strands besitzt die Schleife; ich besitze die Geschäftslogik.
Amazon Bedrock Nova 2
Für die LLM habe ich mich für Amazon Nova 2 Lite entschieden. Warum speziell Nova 2? Ich wollte ein schnelles Modell; das Empfehlen von Cocktails und Getränken ist keine sehr komplexe Aufgabe, also sollte ein kleineres, schnelleres Modell den Job genauso gut erledigen können. Die Antwortzeit ist wichtig, und ein kleineres Modell ist schneller.
Von Anfang an war mein Gedanke, Nova Pro und Nova Lite mit Amazon Bedrock Intelligent Prompt Routing zu verwenden, um je nach Komplexität der Benutzereingabe zwischen den Modellen zu wechseln. Allerdings hatte Nova Pro aus irgendeinem Grund Probleme mit der Tool-Nutzung, und um ehrlich zu sein, ist die Verwendung eines Pro-Modells dafür eine völlige Verschwendung. Also habe ich diese Idee am Ende verworfen.
Das Nova 2 Lite-Modell ist ein großer Schritt vor der ersten Generation von Nova. Das Modell ist schnell, billig und folgt Anweisungen sehr gut. Noch wichtiger ist, dass es Tools zuverlässig aufruft und nicht so viel halluziniert, wenn man ihm strenge Einschränkungen gibt.
AgentCore Memory
Wie wir alle wissen, sind Lambda-Funktionen zustandslos; jede Aufruf beginnt frisch. In einer mehrzügigen Konversation funktioniert das nicht. Wenn ich "Ich mag Gin" sage und dann "Was empfiehlst du mir?", hat die zweite Lambda-Aufruf keine Ahnung, dass du im ersten Interaktion Gin erwähnt hast. Sicher, wir könnten Dinge im Lambda-Speicher speichern, aber in einem Multi-Benutzer-System wird das nicht funktionieren. Ich bin mir nicht sicher, mit welcher Instanz des Lambda-Runtime meine Interaktion endet. Wir brauchen externen Speicher.
AgentCore Memory löst dies, indem es den Gesprächsverlauf an einem zentralen Ort speichert; alle Lambda-Aufrufe können aus diesem Speicher lesen, um das Gespräch frisch zu halten. Jeder Benutzer, der mit der KI interagiert, erhält eine Sitzung, und der Speicher bleibt über Aufrufe hinweg basierend auf dieser Sitzungs-ID bestehen. Wenn der Agent eine neue Nachricht erhält, lädt er den Gesprächsverlauf aus dem Speicher, verarbeitet die Nachricht mit vollem Kontext und speichert den aktualisierten Verlauf zurück.
BartenderMemory:
Type: AWS::BedrockAgentCore::Memory
Properties:
Name: drink_assistant_bartender_memory
EventExpiryDuration: 30 # Tage, um Gesprächsereignisse zu behalten
MemoryStrategies:
- UserPreferenceMemoryStrategy:
Name: DrinkPreferences
Description: Extrahiert Benutzergetränkevoreingenommenheiten
Namespaces:
- preferences/{actorId}Die UserPreferenceMemoryStrategy macht die Dinge interessant. Sie extrahiert Erkenntnisse aus Gesprächen; wenn ein Benutzer mehrmals über Sitzungen hinweg "Ich bevorzuge Gin" sagt, lernt der Speicher dies und macht es für zukünftige Gespräche verfügbar. Kurzzeitspeicher speichert die rohen Gesprächsereignisse, und Langzeitspeicher speichert die extrahierten Muster.
Im Chat-Lambda habe ich den Strands-Sitzungsmanager eingerichtet, um den Speicher zu verwenden – eine sehr saubere und einfache Einrichtung.
from bedrock_agentcore.memory.integrations.strands.session_manager import (
AgentCoreMemorySessionManager
)
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=AgentCoreMemoryConfig(
memory_id=MEMORY_ID, session_id=session_id, actor_id=actor_id
),
region_name=REGION,
)Der Agent ohne Tools
Zu diesem Zeitpunkt habe ich einen grundlegenden funktionierenden Agenten. Er kann Empfehlungen zu Getränken über die Nova 2 LLM geben.
model = BedrockModel(
model_id="global.amazon.nova-2-lite-v1:0",
region_name=REGION,
)
session_manager = create_session_manager(session_id, actor_id)
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
session_manager=session_manager,
)Dieser Agent kann chatten und mit dem Benutzer interagieren; er kann den Kontext über Nachrichten hinweg behalten. Er wird sich wie ein Barkeeper anhören, aber es fehlt eine wichtige Sache, die wir am Anfang angesprochen haben. Er hat keinen Zugriff auf die tatsächliche Getränkekarte; wenn wir nach einer Empfehlung fragen, wird er jedes Getränk vorschlagen, das der LLM sich ausdenkt. Er wird einen Tequila-basierten Cocktail empfehlen, auch wenn ich keine Tequila habe. Er wird sicherlich gerne einen Mojito, einen Cosmopolitan oder andere tolle Cocktails vorschlagen. Er weiß nicht, was ich tatsächlich mixen kann; das ist es, was ich als Nächstes lösen muss.
MCP bietet dem Agenten Zugriff auf Daten
Unsere LLM in Nova kennt sicherlich Tausende von Cocktails, wie wir bereits erwähnt haben. Aber ich möchte nur, dass er die Getränke auf der Speisekarte vorschlägt. Ich könnte natürlich die gesamte Speisekarte im Systemprompt liefern, aber das würde nicht skalieren, wenn die Speisekarte wächst, und wenn ich möchte, dass er Dinge außerhalb der Speisekarte vorschlägt, solange ich die Zutaten habe, nun, dann würde es überhaupt nicht funktionieren; es wäre nicht praktisch.
Die Lösung liegt natürlich in MCP, Model Context Protocol. Es ist ein Standard, um der LLM Tools zur Verfügung zu stellen – Tools, die Daten abrufen können, wie die Speisekarte zum Beispiel. Dann entscheidet das Modell während des Gesprächs, dass es Menüinformationen benötigt, ruft ein Tool auf, erhält die Daten zurück und verwendet sie in der Antwort.
Der Ablauf funktioniert ungefähr so: Ein Benutzer fragt "Welche Gin-Getränke haben Sie?" Der Agent wird erkennen, dass er die Speisekarte braucht, um diese Frage zu beantworten. Er macht einen Tool-Aufruf für, in diesem Fall, getDrinks. Das Tool, implementiert in einer Lambda-Funktion, fragt die Datenbank ab und gibt die Getränkeliste zurück. Nun erhält der Agent diese Liste und empfiehlt nur Getränke, die tatsächlich auf der Speisekarte stehen.
Im Moment habe ich nur das getDrinks-Tool implementiert, aber die Architektur ist flexibel, und das Hinzufügen zusätzlicher Tools ist einfach. Zum Beispiel ein getIngredients-Tool, das zurückgibt, was ich auf Lager habe, ein getPopular-Tool, das Getränke nach Bestellanzahl rangiert, ein orderDrink-Tool, um eine Bestellung aufzugeben. Jedes Tool ist nur eine weitere Lambda-Funktion hinter dem AgentCore-Gateway; der Agent wird schlauer, ohne dass der Systemprompt länger wird.
MCP mit AgentCore-Gateway implementieren
AgentCore-Gateway macht es einfach, Tools für die LLM zu hosten und bereitzustellen. Es unterstützt mehrere verschiedene Zieltypen: OpenAPI-Schema, Lambda und andere externe MCP-Server. Als ich anfing, das Tool aufzubauen, war mein erster Plan, OpenAPI-Schema zu verwenden und es auf die bestehende REST-API zu verweisen – einfach das zu wiederverwenden, was ich bereits gebaut hatte. Macht Sinn, oder?
Falsch! Ich bin auf einige Probleme und Bedenken gestoßen, die mich dazu brachten, dies zu überdenken.
Umstieg auf Lambda-Ziele statt OpenAPI
Das erste Hindernis, auf das ich stieß, war eine Lücke in der CloudFormation-Unterstützung. OpenAPI-Ziele erfordern einen API-Schlüssel-Anmeldeinformationsanbieter für die Authentifizierung; das Gateway benötigt Anmeldeinformationen, um meine API in ihrem Namen aufzurufen. Und hier ist der Haken: CloudFormation hat keine native Ressource für ApiKeyCredentialProvider. Ich müsste es manuell über die Konsole erstellen oder ein Lambda-unterstütztes benutzerdefiniertes Ressource verwenden. Ich bin kein großer Fan von benutzerdefinierten Ressourcen, da sie operationale Komplexität hinzufügen. Für ein Anmeldeinformations, das im Grunde gesetzt und vergessen ist, ist dieser Overhead nicht wert.
Das zweite Problem stellte sich als noch wichtiger heraus: Vertragskopplung. Die aktuelle API wurde gebaut, um Inhalte für meine Web-App zu servieren; sie gab zurück, was die UI zum Rendern brauchte. Das MCP-Tool hat sicherlich andere Anforderungen; als Beispiel braucht es die Bild-URL nicht – es macht einfach keinen Sinn.
Für den KI-Agenten wäre eine kompakte flache JSON-Antwort am optimalsten. Ich könnte in den meisten Fällen sogar nur den Getränkenamen zurückgeben; die LLM weiß, was ein "Gin & Tonic" oder ein "Moscow Mule" ist. Nur bei meinen eigenen speziellen Getränken müsste ich dem Modell möglicherweise mehr Informationen zurückgeben.
Also hatte ich hier ein paar Möglichkeiten: Entweder implementiere ich das "Backend For Frontend"-Architekturmuster und erstelle ein BFF für jeden Client vor der REST-API, oder ich wechsle vollständig und erstelle einfach ein Lambda-Ziel für das AgentCore-Gateway. Am Ende habe ich mich für den zweiten Ansatz entschieden.
# MCP Tool Response (optimized for agent)
{
"drinks": [
{"name": "Negroni", "ingredients": "gin, Campari, sweet vermouth"},
{"name": "Gin & Tonic", "ingredients": "gin, tonic water, lime"}
],
"count": 2
}
# vs REST API Response (optimized for frontend)
{
"items": [...full drink objects with IDs, images, sections...],
"pagination": {"page": 1, "total": 50, "hasMore": true},
"meta": {"cached": true, "timestamp": "..."}
}Der Vorteil dieses Ansatzes ist, dass die API und das MCP-Tool unabhängig voneinander weiterentwickelt werden können. Wenn ich neue Felder zur REST-API für Frontend-Funktionen hinzufüge, wird der Agent nicht betroffen. Eine klare Entkopplung wird geschaffen.
Das getDrinks-Tool
Um das getDrinks-Tool zu implementieren, verbindet sich die Lambda-Funktion zu unserer DSQL-Datenbank und ruft die Liste der Getränke ab. Ich werde nicht darauf eingehen, wie diese Verbindung funktioniert; siehe Teil 1 für Details dazu.
def handler(event, context):
"""MCP tool handler, called by AgentCore Gateway."""
section_id = event.get("section_id")
rows = get_drinks_from_db(section_id)
# Return compact format for the model
drinks = [
{"name": row["name"], "ingredients": ", ".join(row["ingredients"])}
for row in rows
]
return {"drinks": drinks, "count": len(drinks)}Das Antwortformat ist wichtig. Ich habe zunächst vollständige Getränkedetails inklusive Beschreibungen, Bild-URLs und IDs zurückgegeben. Es gibt keinen Sinn, das zu tun, und es würde nur Token verbrauchen; es zu beschneiden, erhöht die Geschwindigkeit und ist kosteneffizienter.
Gateway-CloudFormation
Um unser AgentCore-Gateway wie gewohnt zu erstellen, greife ich auf CloudFormation zurück, und die Einrichtung ist nicht gerade einfach.
BartenderGateway:
Type: AWS::BedrockAgentCore::Gateway
Properties:
Name: drink-assistant-bartender-gateway
ProtocolType: MCP
AuthorizerType: AWS_IAM
DrinksToolsTarget:
Type: AWS::BedrockAgentCore::GatewayTarget
Properties:
GatewayIdentifier: !Ref BartenderGateway
TargetConfiguration:
Mcp:
Lambda:
LambdaArn: !GetAtt McpToolsFunction.Arn
ToolSchema:
InlinePayload:
- Name: getDrinks
Description: >
Retrieves available cocktails from the menu.
Returns drink names and ingredients.Das AgentCore-Gateway verwendet IAM-Authentifizierung mit einem GATEWAY_IAM_ROLE-Anmeldeinformationsanbieter. Die Tool-Beschreibung ist wichtig; sie sagt dem Modell, wann und wie es das Tool verwenden soll. Eine kurze und vage Beschreibung führt dazu, dass das Modell das Tool zur falschen Zeit aufruft oder es überhaupt nicht aufruft, wenn es sollte.
MCP dem Agenten hinzufügen
Jetzt, da wir den MCP über AgentCore bereit sind, müssen wir ihn dem Strands-Agenten bereitstellen, damit er ihn aufrufen kann.
from strands.tools.mcp import MCPClient
from mcp_proxy_for_aws.client import aws_iam_streamablehttp_client
mcp_client = MCPClient(
lambda: aws_iam_streamablehttp_client(GATEWAY_URL, "bedrock-agentcore")
)
tools = mcp_client.list_tools_sync()Der MCPClient von Strands handelt das MCP-Protokoll ab, und mcp-proxy-for-aws fügt IAM-Authentifizierung hinzu, um das AgentCore-Gateway aufzurufen. Ich initialisiere den Client einmal beim Kaltstart und cache die Tools in einem globalen Kontext, damit nachfolgende Anfragen die Einrichtung überspringen, um die Geschwindigkeit von Warmstarts zu verbessern.
tools = get_mcp_tools()
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
session_manager=session_manager,
tools=tools,
)Mit einer einzigen hinzugefügten Zeile kann der Agent jetzt das getDrinks-Tool aufrufen, wenn er die Speisekarte überprüfen muss.
Erstellen des Systemprompts
Das Systemprompt ist das, was die LLM leiten und Anforderungen und Struktur festlegen wird. Erinnerst du dich an das Mojito-Problem aus der Einführung? Das ist es, was wir mit dem Systemprompt vermeiden werden.
Erster Entwurf
Mein erstes Systemprompt war einfach zu einfach und kurz; es gab sehr wenig Anleitung.
System: You are a helpful bartender. When guests ask for drink recommendations,
use the getDrinks tool to see what's available and make suggestions based on
their preferences.Das Ergebnis war höflich, aber unzuverlässig.
Runde zwei, Einschränkungen hinzufügen
In der zweiten Iteration habe ich einige explizite Einschränkungen und Guardrails hinzugefügt.
System: You are a bartender. Use the getDrinks tool to see what drinks are
available. Only recommend drinks that appear in the tool response. Do not
suggest drinks that are not on the menu.Besser, aber es lieferte immer noch nicht das, was ich wollte.
Dritte Iteration
Jetzt habe ich angefangen, einige klare Regeln hinzuzufügen.
System: You are a bartender at a Nordic cocktail bar.
RULES:
- ALWAYS call getDrinks before making recommendations
- ONLY recommend drinks that exist in the getDrinks response
- If a drink is not in the response, say "Sorry, we don't have that"
- Do not describe recipes or ingredients unless they come from the tool
Use descriptive language (fresh, balanced, citrusy) when discussing drinks.Das war viel besser; die LLM hörte auf, Getränke vorzuschlagen, die nicht auf der Speisekarte standen. Aber wenn Gäste vage Fragen wie "Überrasch mich" oder "Was ist beliebt?" stellten, übersprang die LLM manchmal den Tool-Aufruf vollständig und empfahl Getränke, die sie kannte; das Schlüsselwort "ALWAYS" war nicht immer genug.
Letzte Iteration
Am Ende habe ich ein langes Systemprompt erstellt, tatsächlich mit Hilfe von KI. KI zu verwenden, um Prompts für KI zu erstellen, ist tatsächlich ein sehr guter Ansatz und liefert sehr gute Ergebnisse.
SYSTEM_PROMPT = """# BARTENDER AGENT
## CRITICAL RULES - READ FIRST
**YOU MUST NEVER:**
- Suggest drinks that are NOT in the getDrinks result
- Make up ingredients or drinks that don't exist on the menu
- Recommend a drink without first calling getDrinks
**IF A DRINK IS NOT ON THE MENU:**
Say ONLY: "Sorry, we don't have that on the menu. Can I suggest something else?"
**LANGUAGE RULE:**
- Detect the user's language and respond in the same language
- If user writes in Swedish, respond in Swedish
---
## TOOLS
### getDrinks
Fetches drinks from our menu.
- ALWAYS call this tool when the guest asks for recommendations
- This is your ONLY source for drink information
- Recommend ONLY drinks that exist in the response
## IDENTITY
...
## CONVERSATION FLOW
...
## LIMITATIONS
...
"""Das Platzieren von "CRITICAL RULES - READ FIRST" oben mit fetter Formatierung signalisiert Wichtigkeit; "YOU MUST NEVER" ist stärker als "do not" oder "avoid", und das genaue Angeben, was zu sagen ist, wenn ein Getränk nicht verfügbar ist, entfernt Mehrdeutigkeit; das Modell muss nicht herausfinden, wie es eine Ablehnung formulieren soll.
Ich habe auch die Spracherkennungsregel hinzugefügt, nachdem ich bemerkt hatte, dass der Agent auf Englisch antwortete, selbst wenn ich auf Schwedisch fragte. Diese können sich wie kleine Details anfühlen, aber sie summieren sich zu einem besseren Erlebnis.
Testen
Nach jeder Prompt-Iteration habe ich die gleichen Testszenarien durchgeführt, damit ich die Verbesserungen einfacher nachverfolgen konnte, als wenn ich nur zufällige Dinge gefragt hätte.
- Direkte Übereinstimmung: "Ich möchte einen Negroni" (wir haben ihn)
- Keine Übereinstimmung: "Kann ich eine Piña Colada bekommen?" (wir haben sie nicht)
- Vage Anfrage: "Etwas Erfrischendes mit Gin"
- Herausforderung: "Was ist mit einem Mojito mit Wassermelone?" (testet, ob es Variationen erfindet)
- Off-Topic: "Wie ist das Wetter?" (soll in der Rolle bleiben)
Das endgültige Prompt hat alle fünf Tests mit Bravour bestanden. Frühere Versionen würden einige der Szenarien nicht bestehen.
Beim Aufbau von KI-Agenten ist das Systemprompt einer unserer primären Steuerungen. Es ist wichtig, dass wir explizit, repetitiv sind und die wichtigsten Regeln dort platzieren, wo das Modell sie zuerst sieht.
Die agentische Schleife
Ich habe die agentische Schleife bereits ein paar Mal erwähnt, aber was ist sie im Detail? Wie funktioniert sie wirklich? Ich werde versuchen, das zu erklären.
Ein Benutzer beginnt, indem er dem Agenten eine Frage stellt oder ihm einen direkten Befehl gibt – etwas wie "Ich möchte etwas mit Gin" in der React-Frontends. Das Frontend sendet dies per POST an den /chat-Endpunkt. API Gateway ruft die Streaming-Lambda über die /response-streaming-invocations auf, und der Lambda Web Adapter startet FastAPI, die die Anfrage verarbeitet. Der Lambda-Handler lädt MCP-Tools, initialisiert den Strands-Agenten, der alles starten wird.
Strands beginnt, indem es die Nachricht des Benutzers an die Nova 2 LLM sendet, zusammen mit dem Systemprompt, den wir früher definiert haben, und jedem Gesprächsverlauf aus früheren Nachrichten, den es von AgentCore Memory abruft. Das Modell liest das Systemprompt, sieht die kritischen Regeln über das immer Aufrufen von getDrinks, und entscheidet, dass es Menüdaten braucht, bevor es irgendetwas empfehlen kann; dies lässt es einen Tool-Aufruf machen.
Strands nimmt das Ergebnis des Tool-Aufrufs auf und gibt das Ergebnis zurück an das Modell.
Jetzt hat das Modell die tatsächliche Speisekarte, filtert für Gin-basierte Getränke, berücksichtigt die anderen Vorlieben des Gastes und erstellt eine Empfehlung. Jeder Token wird jetzt über Strands, über FastAPIs StreamingResponse, über API Gateway und in das Frontend gestreamt, und AgentCore Memory speichert das Gespräch für das nächste Mal.
Hier ist der Kern des Streaming-Endpunkts.
async def stream_response():
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
tools=get_mcp_tools(),
session_manager=create_session_manager(session_id, actor_id),
)
async for event in agent.stream_async(message):
if isinstance(event, dict) and event.get("data"):
yield f"data: {json.dumps({'chunk': event['data'], 'sessionId': session_id})}\n\n"
yield f"data: {json.dumps({'done': True, 'sessionId': session_id})}\n\n"
return StreamingResponse(stream_response(), media_type="text/event-stream")Die stream_async-Methode ist der Ort, an dem die agentische Schleife lebt. Strands handelt den benötigten Hin- und Herwechsel zwischen dem Modell und den Tools intern ab. Aus der Perspektive meines Codes iteriere ich einfach über Ereignisse und gebe Textstücke als Server-Sent Events aus. Strands entscheidet, wann das Modell einen weiteren Tool-Aufruf braucht und wann es bereit ist zu antworten.

Kosten
Für gelegentlichen Heimgebrauch ist dies im Wesentlichen kostenlos.
| Komponente | Kosten |
|---|---|
| Bedrock Nova 2 Lite | ~$0.001/1K Eingabe, ~$0.002/1K Ausgabe-Token |
| Lambda | ~$0.0000166 pro GB-Sekunde |
| AgentCore Memory | Inklusive bei Bedrock |
| AgentCore Gateway | Inklusive bei Bedrock |
| Aurora DSQL | Bezahlt pro Anfrage, minimal bei niedrigem Verkehr |
Eine typische Konversation kostet Bruchteile eines Cents. Selbst mit einer Gruppe von 20 Personen, die den ganzen Abend Fragen stellen, würde die Gesamtsumme unter einem Dollar liegen.
Was kommt als Nächstes
Der KI-Barkeeper ist jetzt fertig; alle drei Teile sind abgeschlossen.
In Teil 1 habe ich die serverlose Grundlage mit Aurora DSQL, APIs, Authentifizierung und ereignisgesteuerter Bildprompt-Generierung abgedeckt. Teil 2 fügte Gästeanmeldung mit Einladungscodes, selbstunterzeichneten JWTs und Echtzeit-Bestellupdates mit AppSync Events hinzu. In diesem letzten Teil 3 habe ich den KI-Chat-Agenten mit Strands, MCP-Tools, AgentCore Memory und Antwort-Streaming gebaut.
Zukünftige Ideen umfassen die Erweiterung der Tools, das Hinzufügen von Zutateninventar, vielleicht aus einem Bild. Nur meine eigene Vorstellung setzt die Grenzen.
Abschließende Worte
Was als eine Lösung begann, um nicht mehr der menschliche Getränkemenu auf einer Hausparty zu sein, entwickelte sich zu einem tiefen Eintauchen in serverlose, ereignisgesteuerte und KI-Technologien. Jeder Teil brachte seine eigenen Herausforderungen und Probleme mit sich, die großartig zu lösen waren.
Der vollständige Quellcode ist auf GitHub verfügbar.
Schau dir meine anderen Beiträge auf jimmydqv.com an und folge mir auf LinkedIn und X für mehr Serverless-Inhalte.
Jetzt baue ich!