Creando un Barman IA Sin Servidor - Parte 3: El Agente de Chat IA

Este archivo ha sido traducido automaticamente por IA, pueden ocurrir errores
En la Parte 1 construí la base con Aurora DSQL, APIs y flujos de trabajo impulsados por eventos. En la Parte 2 añadí el registro de invitados y actualizaciones en vivo de pedidos con AppSync Events. Los invitados pueden explorar bebidas y realizar pedidos. Pero sigue siendo solo un menú digital.
Aquí es donde entra la IA. El objetivo principal de este pequeño proyecto era que no tuviera que ser yo el menú. Quería un menú digital pero también un Asistente de Cócteles IA que pudiera recomendar bebidas en lugar de yo. Necesitaba construir algo que entienda preferencias, recomiende bebidas, pero solo sugiera bebidas que realmente pueda preparar.
Esa última parte trajo varios desafíos; me tomó unos días adicionales para conseguir las cosas como quería. La primera vez que probé el chatbot, recomendó un "Mojito", pero no tenía "Mojito" en el menú. La IA sugirió buenas bebidas pero no verificó si era posible prepararla. Aprendí que construir agentes IA no se trata solo de conectarse a un modelo de lenguaje. Se trata de controlar lo que el modelo puede y no puede decir.
El código fuente completo de este proyecto está disponible en GitHub.
Vamos a construir el barman IA.
El Barman en Acción
Antes de adentrarnos en los detalles técnicos, permítanme mostrarles lo que estamos construyendo. Esta es la interfaz de chat real que los invitados pueden usar.
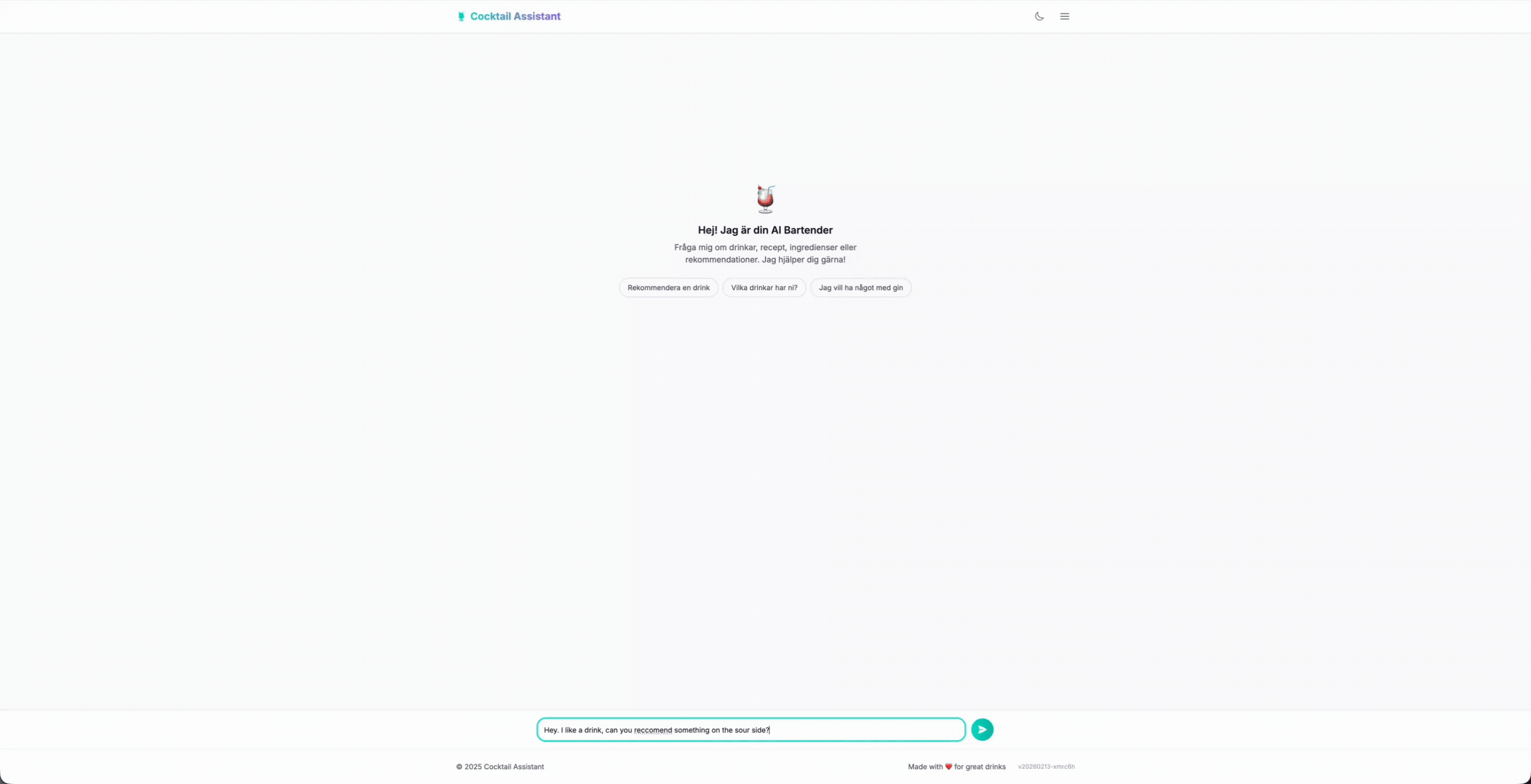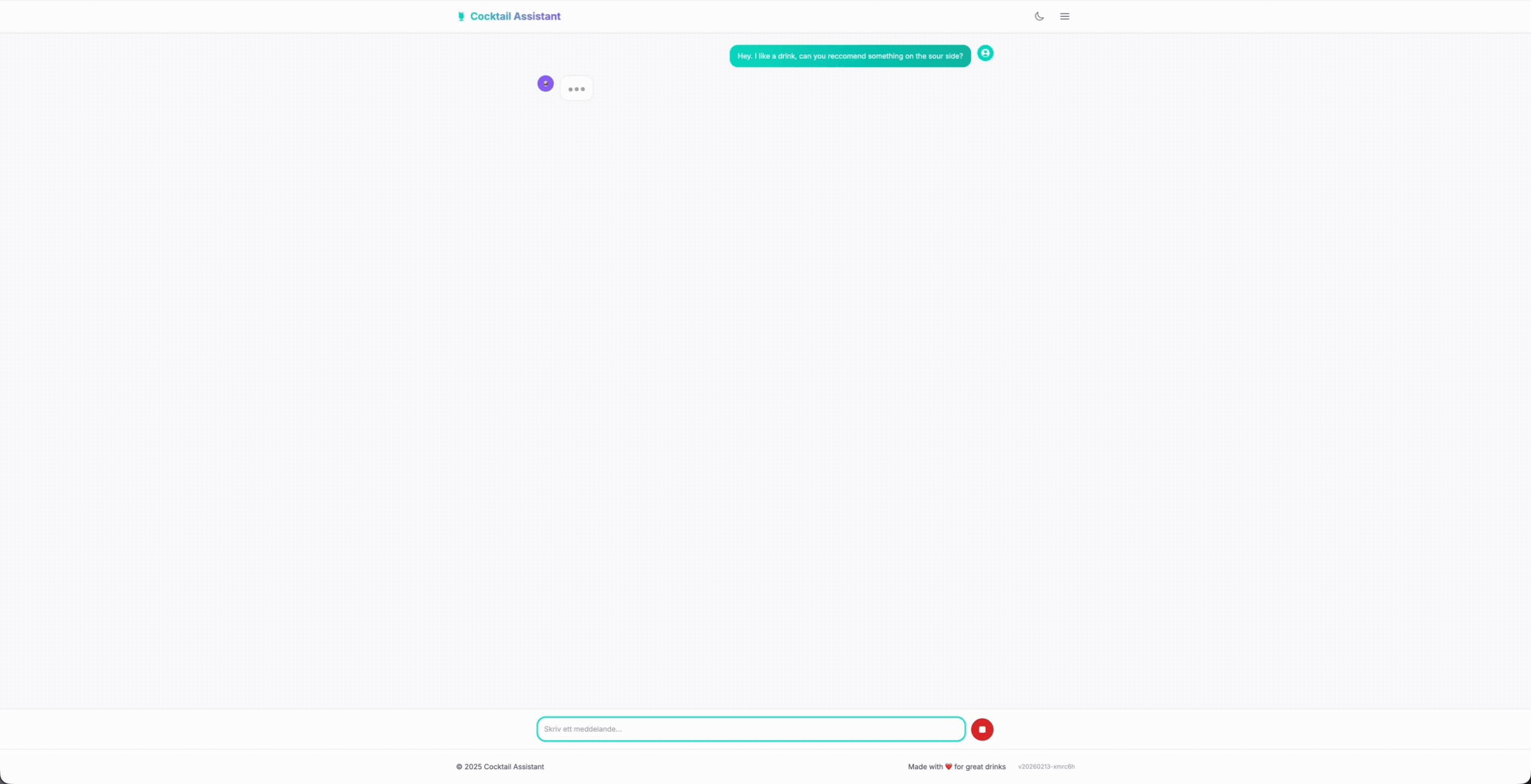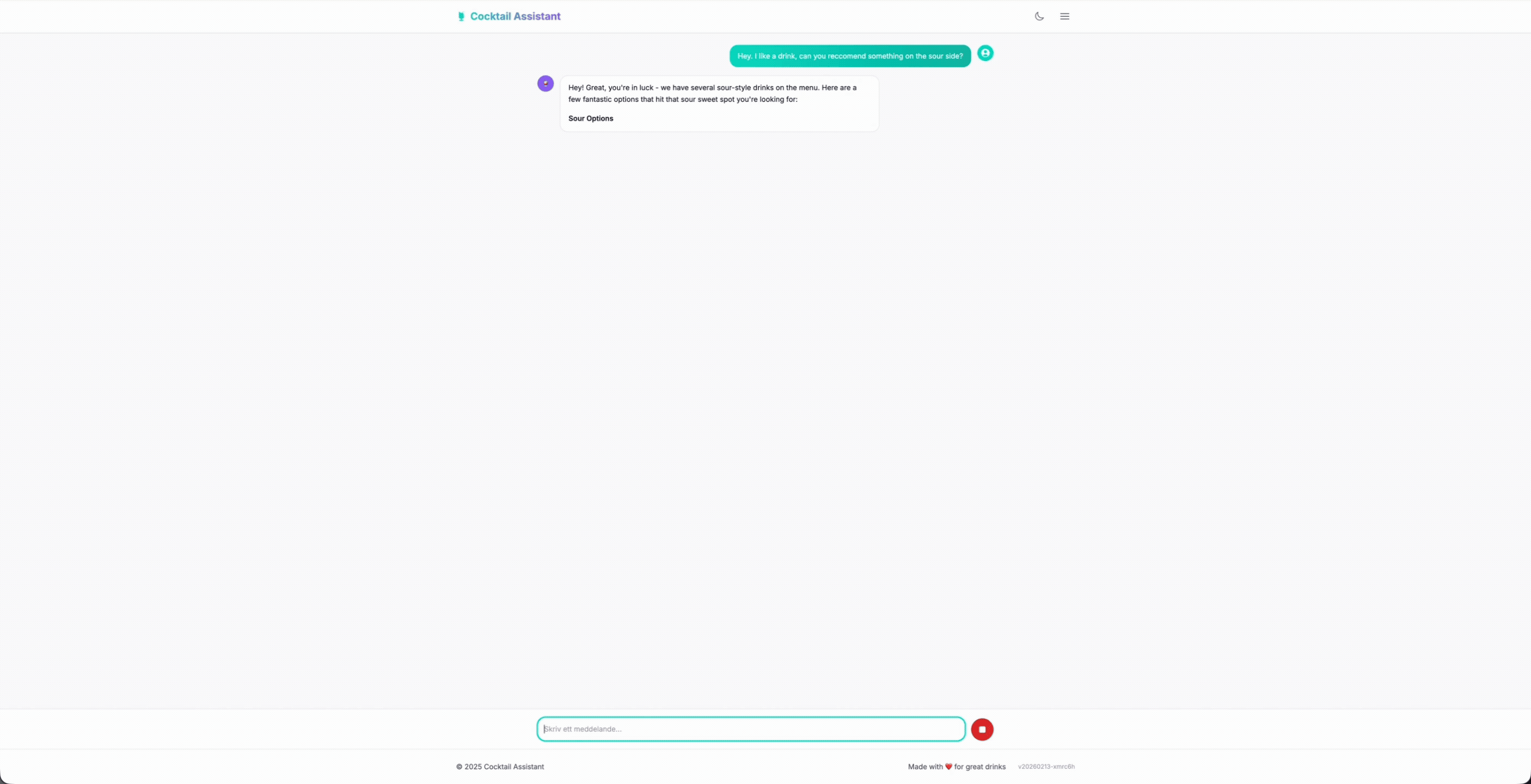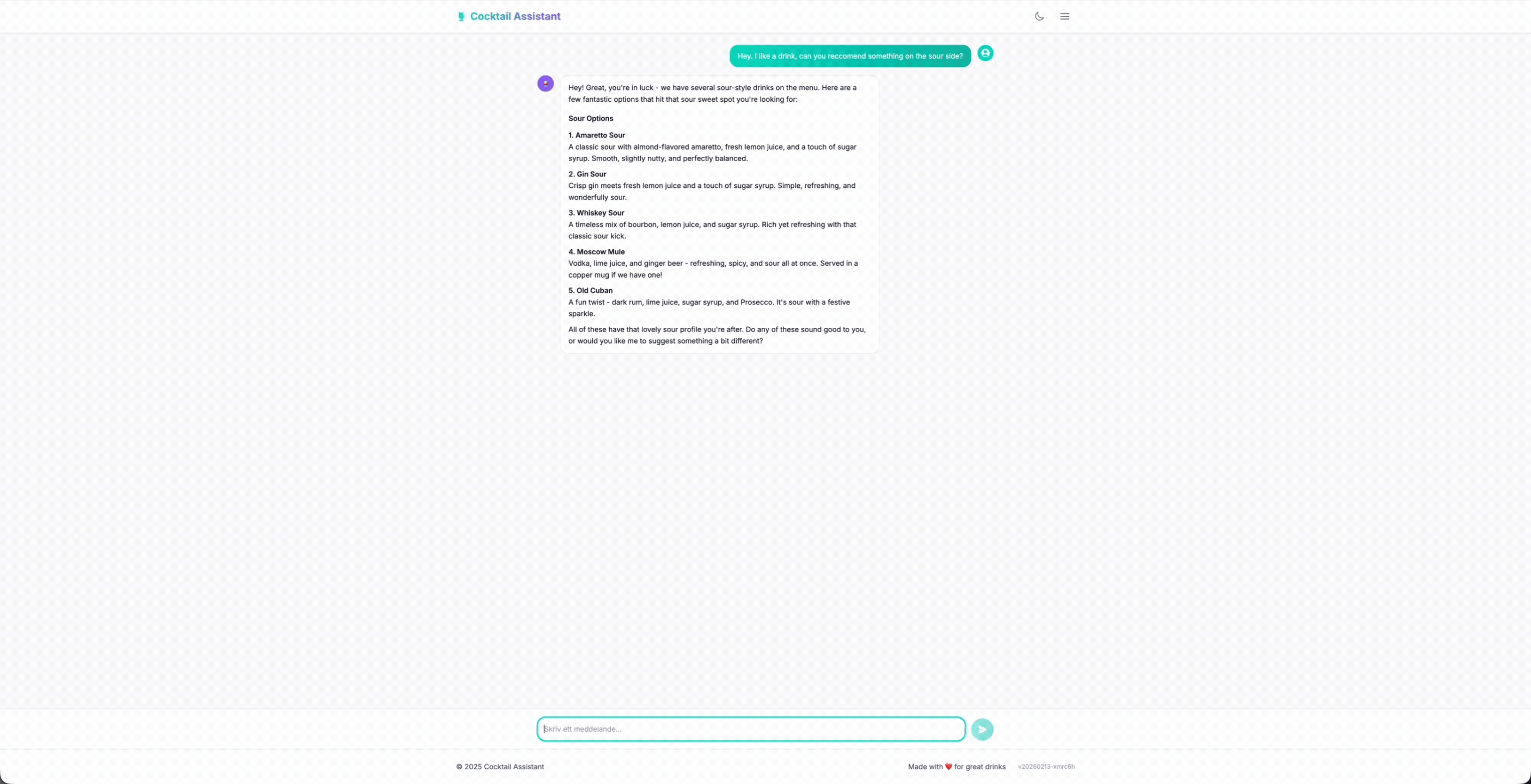
La conversación fluye naturalmente; el usuario pide bebidas, añade sus preferencias como dulce, ácido, amargo, etc. El barman responde, obtiene el menú y recomienda bebidas que realmente existen. Cuando alguien pide algo que no tenemos, redirige educadamente en lugar de inventar cosas.
Lo que no ven es todo lo que sucede detrás de esa interfaz. El agente llama a mis herramientas MCP para obtener el menú, carga el historial de conversación desde AgentCore Memory, transmite la respuesta palabra por palabra a través de Lambda Web Adapter y sigue reglas estrictas para evitar alucinaciones. Todo invisible para el invitado. Todo haciendo que la experiencia se sienta como si estuviera hablando con un barman real.
Visión general de la arquitectura
Echemos un vistazo a la arquitectura y los servicios que utilizaremos para construir el chatbot del Barman IA.
Tengo el frontend en React llamando a AWS Api Gateway; esto está creado y configurado con respuesta en streaming. Para implementar la lógica, por supuesto, recurro a Lambda, que está configurado como integración con la API. Para manejar el bucle agente de manera fácil, Strands Agents viene al rescate. Nuestra función Lambda, con Strands, luego interactúa con Amazon Bedrock y usa Amazon Nova 2 Lite como LLM. Amazon AgentCore proporciona algunas partes muy importantes: memoria para mantener la conversación y puerta de enlace para llegar a mis herramientas MCP. ¡Esto crea una solución estable, rentable y sin servidor!

API de Chat con Streaming
Lo primero que necesité fue crear un punto final de API para el chat. Ya tenemos un API Gateway desde la Parte 1 y 2 que maneja todos los extremos REST: explorar bebidas, gestionar el menú, realizar pedidos. Mi primer instinto fue simplemente expandir esa API y añadir una ruta /chat allí. Eso no funcionó realmente como quería.
La API principal usa la propiedad Events de SAM en las funciones Lambda para definir extremos. Así es como normalmente lo configuro, aunque tiene algunos defectos. Es demasiado simple para patrones de solicitud-respuesta estándar, no para esto. Pero necesitaba streaming de respuestas para el chat, y los Eventos SAM no admiten responseTransferMode en este momento. Simplemente no había forma de configurarlo de la manera normal.
Para que esto funcionara, tuve que usar una especificación OpenAPI y configurar responseTransferMode en STREAM, ya que no sería posible mantener la API actual y simplemente añadir la especificación OpenAPI para el nuevo extremo; la solución se convirtió en una pila dedicada para la API de chat. Así que creé un AWS::Serverless::Api separado con un DefinitionBody OpenAPI. Un beneficio que viene con esto es que desacoplo las APIs; puedo desplegar la API de menú basada en REST y la API de Chat IA por separado. Los cambios en el chat no arriesgan romper el flujo de pedidos y viceversa.
paths:
/chat:
post:
x-amazon-apigateway-integration:
type: aws_proxy
httpMethod: POST
responseTransferMode: "STREAM"
uri:
Fn::Sub: >-
arn:aws:apigateway:${AWS::Region}:lambda:path/2021-11-15/functions/${ChatStreamingFunction.Arn}/response-streaming-invocationsPrimero, como ya se mencionó, responseTransferMode: "STREAM" le indica a API Gateway que transmita la respuesta en lugar de bufferizarla. Segundo, la ruta URI usa /response-streaming-invocations en lugar de las normales /invocations. Esta es una API de invocación Lambda diferente que admite transferencia en trozos. Sin ambas cosas, API Gateway esperaría la respuesta completa de Lambda antes de enviar algo al cliente.
Streaming de Respuestas
¿Por qué pasar por todo este problema y saltar todos estos obstáculos solo por streaming? Porque la diferencia en la experiencia del usuario es enorme.
La primera versión que construí del chat era síncrona; era más fácil así. Lambda esperaba la respuesta completa de Bedrock, luego devolvía todo de una vez. Pero no fluía naturalmente; todos hoy en día están acostumbrados a que las respuestas lleguen en streams. ChatGPT, Claude, Gemini y básicamente todos los chats IA están construidos así.
Con streaming, el usuario ve la primera palabra en milisegundos en lugar de esperar segundos por la respuesta completa. El resto fluye palabra por palabra; al final el tiempo total es más o menos el mismo, pero se siente mucho más suave y, como humanos, lo experimentamos como más natural.
El término técnico para todo esto es "tiempo hasta el primer token" versus "tiempo hasta el último token". Para respuestas bufferizadas, ambos son iguales. Para streaming, el tiempo hasta el primer token es típicamente menor de un segundo. ¡Ese primer token es lo que importa!
También hay un beneficio práctico. Si el modelo comienza a generar tonterías o se atasca en un bucle, el usuario lo ve inmediatamente y puede cancelar.
Lambda Web Adapter para Streaming en Python
Ahora, hay un problema con todo esto. Python Lambda no admite nativamente el streaming de respuestas. Solo Node.js tiene soporte integrado de streaming a través de la API de streaming de respuestas de Lambda. Pero quería construir el agente en Python porque Python es mi lenguaje preferido, y como todo lo demás en el backend es basado en Python, quería intentar mantenerlo así.
La solución aquí es usar Lambda Web Adapter. Es una capa Lambda publicada por AWS que envuelve tu marco web—en mi caso FastAPI—y traduce entre la API de invocación streaming de Lambda y las respuestas HTTP estándar. Escribes una aplicación FastAPI normal con StreamingResponse, y el adaptador maneja el resto.
ChatStreamingFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/chat-streaming/
Handler: run.sh
Runtime: python3.13
Architectures:
- arm64
Timeout: 120
MemorySize: 1024
Layers:
# Capa Lambda Web Adapter publicada por AWS
- !Sub arn:aws:lambda:${AWS::Region}:753240598075:layer:LambdaAdapterLayerArm64:25
Environment:
Variables:
AWS_LAMBDA_EXEC_WRAPPER: /opt/bootstrap
PORT: 8080
AWS_LWA_INVOKE_MODE: RESPONSE_STREAMHay tres variables de entorno que hacen que esto funcione al final. AWS_LAMBDA_EXEC_WRAPPER le dice a Lambda que use el adaptador como punto de entrada en lugar de llamar a tu manejador directamente. PORT le dice al adaptador dónde está escuchando tu aplicación FastAPI. Y AWS_LWA_INVOKE_MODE configurado en RESPONSE_STREAM habilita la codificación de transferencia en trozos que hace posible el streaming.
El manejador Lambda es simplemente un pequeño script de shell de dos líneas que iniciará el servidor FastAPI.
#!/bin/bash
exec python handler.pyEl adaptador interceptará las solicitudes de la API streaming de Lambda, las reenviará a FastAPI sobre HTTP en el puerto 8080 y luego transmitirá la respuesta trozo a trozo. Desde la perspectiva de mi código, solo estoy escribiendo una aplicación FastAPI normal. La parte de streaming está manejada completamente por la capa.
Así que al final, esto se convierte en una solución bastante fluida. Puedes encontrar la solución en Serverless Land también.
Dentro de la Lambda de Chat
Con la API y el streaming en su lugar, echemos un vistazo a lo que realmente se ejecuta dentro de la función Lambda.
Strands Agents
Al construir un agente IA desde cero, tenemos que implementar muchas cosas: enviar el mensaje del usuario al modelo, verificar si el modelo quiere llamar a una de nuestras herramientas, llamar a la herramienta, enviar el resultado de vuelta al LLM, verificar de nuevo y seguir iterando hasta que el modelo tenga una respuesta final. Básicamente necesitamos implementar lo que a menudo se denomina el Bucle Agente. Luego añadimos streaming, recuperación de errores y estado de conversación encima.
Strands Agents es un SDK de código abierto de AWS que nos ayuda a implementar el Bucle Agente. Nos ayuda a reducir el tiempo de implementación de semanas a días. Ejecutará el bucle agente por nosotros. Cuando el modelo decida que necesita revisar el menú, Strands invoca la llamada a la herramienta, alimenta el resultado de vuelta y continúa hasta que el modelo esté contento y tenga una respuesta completa. También se integra directamente con AgentCore Memory para la gestión de sesiones y admite streaming asíncrono.
La configuración básica es sorprendentemente fácil.
from strands import Agent
from strands.models.bedrock import BedrockModel
model = BedrockModel(model_id="amazon.nova-2-lite-v1:0")
agent = Agent(model=model, system_prompt="Eres un barman.")
for chunk in agent.stream("Sugiere una bebida de ginebra"):
print(chunk, end="")Tres líneas y tienes un agente IA con streaming. Strands se encarga del bucle; yo me encargo de la lógica de negocio.
Amazon Bedrock Nova 2
Para el LLM, opté por Amazon Nova 2 Lite. ¿Por qué Nova 2 específicamente? Quería un modelo rápido; recomendar cócteles y bebidas no es una tarea muy compleja, así que un modelo más pequeño y rápido debería poder hacer el trabajo bien. El tiempo de respuesta importa, y un modelo más pequeño es más rápido.
Desde el principio mi pensamiento fue usar Nova Pro y Nova Lite con Amazon Bedrock Intelligent Prompt Routing para cambiar entre los modelos dependiendo de la complejidad de la entrada del usuario. Sin embargo, por alguna razón Nova Pro luchó un poco con el uso de herramientas, y para ser honesto, usar un modelo pro para esto es un completo desperdicio. Así que al final abandoné esa idea.
El modelo Nova 2 Lite es un gran paso adelante de la primera generación de Nova. El modelo es rápido, barato y sigue las instrucciones muy bien. Más importante aún, llama a las herramientas de manera confiable y no alucina tanto cuando le das restricciones estrictas.
AgentCore Memory
Como todos sabemos, las funciones Lambda son sin estado; cada invocación comienza desde cero. En una conversación de varios turnos esto no funciona. Si pregunto "Me gusta la ginebra" y luego "¿Qué me recomiendas?", la segunda invocación de Lambda no tiene idea de que mencionaste la ginebra en la primera interacción. Claro, podríamos almacenar cosas en la memoria de Lambda, pero en un sistema multiusuario eso no funcionará. No estoy seguro de en qué instancia del tiempo de ejecución de Lambda termina mi interacción. Necesitamos memoria externa.
AgentCore Memory resuelve esto almacenando el historial de conversación en un lugar central; todas las invocaciones de Lambda pueden leer de esta memoria para tener la conversación actualizada. Cada usuario que interactúa con la IA obtiene una sesión, y la memoria persiste entre invocaciones basándose en ese ID de sesión. Cuando el agente recibe un nuevo mensaje, carga el historial de conversación desde la memoria, procesa el mensaje con todo el contexto y guarda el historial actualizado de vuelta.
BartenderMemory:
Type: AWS::BedrockAgentCore::Memory
Properties:
Name: drink_assistant_bartender_memory
EventExpiryDuration: 30 # Días para mantener los eventos de conversación
MemoryStrategies:
- UserPreferenceMemoryStrategy:
Name: DrinkPreferences
Description: Extrae preferencias de bebida del usuario
Namespaces:
- preferences/{actorId}La UserPreferenceMemoryStrategy hace las cosas interesantes. Extrae ideas de las conversaciones; si un usuario dice "Prefiero ginebra" varias veces en diferentes sesiones, la memoria lo aprende y lo hace disponible para futuras conversaciones. La memoria a corto plazo almacena los eventos crudos de conversación, y la memoria a largo plazo almacena los patrones extraídos.
En la Lambda de chat, configuré el administrador de sesiones de Strands para usar la memoria—una configuración muy limpia y fácil.
from bedrock_agentcore.memory.integrations.strands.session_manager import (
AgentCoreMemorySessionManager
)
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=AgentCoreMemoryConfig(
memory_id=MEMORY_ID, session_id=session_id, actor_id=actor_id
),
region_name=REGION,
)El Agente Sin Herramientas
En este punto, tengo un agente básico que funciona. Puede dar recomendaciones sobre bebidas a través del LLM Nova 2.
model = BedrockModel(
model_id="global.amazon.nova-2-lite-v1:0",
region_name=REGION,
)
session_manager = create_session_manager(session_id, actor_id)
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
session_manager=session_manager,
)Este agente puede chatear e interactuar con el usuario; puede recordar el contexto entre mensajes. Sonará como un barman, pero falta una cosa importante que tocamos al principio. No tiene acceso al menú de bebidas real; si le pedimos una recomendación, sugerirá cualquier bebida que el LLM se le ocurra. Sugerirá un cóctel a base de tequila incluso si no tengo tequila. Seguro que sugerirá un Mojito, un Cosmopolitan o cualquier otro cóctel increíble que exista. No sabe lo que realmente puedo preparar; eso es lo que necesito resolver a continuación.
MCP Proporcionando Acceso a Datos al Agente
Nuestro LLM en Nova definitivamente conoce miles de cócteles, como ya hemos mencionado. Pero solo quiero que sugiera las bebidas del menú. Podría, por supuesto, proporcionar el menú completo en la instrucción del sistema, pero eso no escalaría a medida que el menú crece, y si quiero que sugiera cosas fuera del menú siempre y cuando tenga los ingredientes, bueno, entonces no funcionaría en absoluto; no sería práctico.
La solución, por supuesto, radica en MCP, Model Context Protocol. Es un estándar para darle al LLM herramientas para usar—herramientas que pueden obtener datos, como el menú por ejemplo. Entonces el modelo decide durante la conversación que necesita información del menú, llama a una herramienta, obtiene los datos de vuelta y los usa en la respuesta.
El flujo funciona más o menos así: Un usuario pregunta "¿qué bebidas de ginebra tienes?" El agente reconocerá que necesita el menú para responder a esa pregunta. Hace una llamada a la herramienta para, en este caso, getDrinks. La herramienta, implementada en una función Lambda, consulta la base de datos y devuelve la lista de bebidas. Ahora, el agente recibe esa lista y recomienda solo bebidas que realmente están en el menú.
En este momento solo he implementado la herramienta getDrinks, pero la arquitectura es flexible, y construir herramientas adicionales es fácil. Por ejemplo, una herramienta getIngredients que devuelva lo que tengo en stock, una herramienta getPopular que clasifique las bebidas por número de pedidos, una herramienta orderDrink para realizar un pedido. Cada herramienta es solo otra función Lambda detrás de la puerta de enlace AgentCore; el agente se vuelve más inteligente sin que la instrucción del sistema se vuelva más larga.
Implementando MCP con AgentCore Gateway
AgentCore Gateway hace que sea fácil alojar y proporcionar herramientas al LLM. Admite múltiples tipos de destino: Esquema OpenAPI, Lambda y otros servidores MCP externos. Cuando comencé a construir la herramienta, mi primer plan fue usar OpenAPI Schema y apuntarlo a la API REST existente—simplemente reutilizar lo que ya había construido. ¿Tiene sentido, verdad?
¡Error! Me encontré con algunos problemas y preocupaciones que me hicieron reconsiderarlo.
Cambiando a Destinos Lambda desde OpenAPI
El primer obstáculo en el que me encontré fue una brecha en el soporte de CloudFormation. Los destinos OpenAPI requieren un proveedor de credenciales de API key para la autenticación; la Puerta de enlace necesita credenciales para llamar a mi API en su nombre. Y aquí está el problema: CloudFormation no tiene un recurso nativo para ApiKeyCredentialProvider. Tendría que crearlo manualmente a través de la consola o usar un Recurso Personalizado respaldado por Lambda. No soy un gran fan de los Recursos Personalizados ya que añaden complejidad operativa. Para una credencial que básicamente se configura y se olvida, esta sobrecarga no vale la pena.
El segundo problema resultó ser aún más importante: acoplamiento de contrato. La API actual fue construida para servir contenido a mi webapp; devolvía lo que la UI necesitaba para renderizarse. La herramienta MCP definitivamente tiene diferentes requisitos; como ejemplo, no necesita la URL de la imagen—simplemente no tiene sentido.
Para el Agente IA, una respuesta JSON plana y compacta sería lo más óptimo. En la mayoría de los casos incluso podría devolver solo el nombre de la bebida; el LLM sabe qué es un "Gin & Tonic" o un "Moscow Mule". Es solo para mis bebidas personalizadas que podría necesitar devolver más información al modelo.
Así que tuve unas cuantas opciones aquí: o implementar el patrón de arquitectura "Backend For Frontend" y crear un BFF para cada cliente frente a la API REST, o cambiar por completo y simplemente crear un destino Lambda para AgentCore Gateway. Al final opté por la segunda aproximación.
# Respuesta de la Herramienta MCP (optimizada para el agente)
{
"drinks": [
{"name": "Negroni", "ingredients": "gin, Campari, sweet vermouth"},
{"name": "Gin & Tonic", "ingredients": "gin, tonic water, lime"}
],
"count": 2
}
# vs Respuesta de la API REST (optimizada para el frontend)
{
"items": [...objetos completos de bebida con IDs, imágenes, secciones...],
"pagination": {"page": 1, "total": 50, "hasMore": true},
"meta": {"cached": true, "timestamp": "..."}
}El beneficio de este enfoque es que la API y la herramienta MCP pueden evolucionar independientemente. Cuando añado nuevos campos a la API REST para características del frontend, el agente no se ve afectado. Creando un desacoplamiento claro.
La Herramienta getDrinks
Para implementar la herramienta getDrinks, la función Lambda se conecta a nuestra base de datos DSQL y obtiene la lista de bebidas. No entraré en cómo funciona esa conexión; ver Parte 1 para detalles al respecto.
def handler(event, context):
"""Manejador de la herramienta MCP, llamado por AgentCore Gateway."""
section_id = event.get("section_id")
rows = get_drinks_from_db(section_id)
# Devolver formato compacto para el modelo
drinks = [
{"name": row["name"], "ingredients": ", ".join(row["ingredients"])}
for row in rows
]
return {"drinks": drinks, "count": len(drinks)}El formato de la respuesta importa. Inicialmente devolví detalles completos de la bebida incluyendo descripciones, URLs de imágenes y IDs. No tiene sentido hacer eso, y solo consumiría tokens; recortarlo aumenta la velocidad y es más eficiente en costos.
Gateway CloudFormation
Para crear nuestro AgentCore Gateway como es normal, recurro a CloudFormation, y la configuración no es sencillamente directa.
BartenderGateway:
Type: AWS::BedrockAgentCore::Gateway
Properties:
Name: drink-assistant-bartender-gateway
ProtocolType: MCP
AuthorizerType: AWS_IAM
DrinksToolsTarget:
Type: AWS::BedrockAgentCore::GatewayTarget
Properties:
GatewayIdentifier: !Ref BartenderGateway
TargetConfiguration:
Mcp:
Lambda:
LambdaArn: !GetAtt McpToolsFunction.Arn
ToolSchema:
InlinePayload:
- Name: getDrinks
Description: >
Retrieves available cocktails from the menu.
Returns drink names and ingredients.La puerta de enlace AgentCore usa autenticación IAM con un proveedor de credenciales GATEWAY_IAM_ROLE. La descripción de la herramienta es importante; le dice al modelo cuándo y cómo usar la herramienta. Una descripción corta y vaga lleva a que el modelo llame a la herramienta en momentos equivocados o no la llame cuando debería.
Añadiendo MCP al Agente
Ahora que tenemos el MCP listo para usar a través de AgentCore, necesitamos proporcionárselo al agente Strands para que pueda llamarlo.
from strands.tools.mcp import MCPClient
from mcp_proxy_for_aws.client import aws_iam_streamablehttp_client
mcp_client = MCPClient(
lambda: aws_iam_streamablehttp_client(GATEWAY_URL, "bedrock-agentcore")
)
tools = mcp_client.list_tools_sync()El MCPClient de Strands maneja el protocolo MCP, y mcp-proxy-for-aws añade autenticación IAM para llamar a la puerta de enlace AgentCore. Inicializo el cliente una vez en el inicio en frío y cachéo las herramientas en un contexto global para que las solicitudes posteriores se salten la configuración, para mejorar la velocidad de los inicios en calor.
tools = get_mcp_tools()
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
session_manager=session_manager,
tools=tools,
)Con una sola línea añadida, el agente ahora puede llamar a la herramienta getDrinks cuando necesite revisar el menú.
Creando la instrucción del sistema
La instrucción del sistema es lo que guiará al LLM y establecerá requisitos y estructura. ¿Recuerdas el problema del Mojito de la introducción? Eso es lo que evitaremos con la instrucción del sistema.
Primer borrador
Mi primera instrucción del sistema era demasiado simple y corta; proporcionaba muy poca guía.
System: Eres un barman útil. Cuando los invitados piden recomendaciones de bebidas,
usa la herramienta getDrinks para ver qué está disponible y haz sugerencias basadas en
sus preferencias.El resultado fue educado pero poco confiable.
Segunda ronda, añadiendo restricciones
En la segunda iteración añadí algunas restricciones y guardrails explícitos.
System: Eres un barman. Usa la herramienta getDrinks para ver qué bebidas están
disponibles. Solo recomienda bebidas que aparezcan en la respuesta de la herramienta. No
sugieras bebidas que no estén en el menú.Mejor, pero aún no proporcionaba lo que quería.
Tercera iteración
Ahora comencé a añadir algunas reglas claras.
System: Eres un barman en un bar de cócteles nórdico.
REGLAS:
- SIEMPRE llama a getDrinks antes de hacer recomendaciones
- SOLO recomienda bebidas que existan en la respuesta de getDrinks
- Si una bebida no está en la respuesta, di "Lo siento, no tenemos eso"
- No describas recetas o ingredientes a menos que vengan de la herramienta
Usa lenguaje descriptivo (fresco, equilibrado, cítrico) al hablar de bebidas.Esto fue mucho mejor; el LLM dejó de sugerir bebidas que no estaban en el menú. Pero cuando los invitados hacían preguntas vagas como "sorpréndeme" o "¿qué es popular?", el LLM a veces saltaba la llamada a la herramienta por completo y recomendaba bebidas que conocía; la palabra clave "SIEMPRE" no siempre era suficiente.
Iteración final
Al final creé una instrucción del sistema larga, en realidad con ayuda de IA. Usar IA para crear instrucciones para IA es en realidad un enfoque muy bueno y crea muy buenos resultados.
SYSTEM_PROMPT = """# AGENTE BARMAN
## REGLAS CRÍTICAS - LEE PRIMERO
**NUNCA DEBES:**
- Sugerir bebidas que NO estén en el resultado de getDrinks
- Inventar ingredientes o bebidas que no existan en el menú
- Recomendar una bebida sin llamar primero a getDrinks
**SI UNA BEBIDA NO ESTÁ EN EL MENÚ:**
Di SOLO: "Lo siento, no tenemos eso en el menú. ¿Puedo sugerirte algo más?"
**REGLA DE LENGUAJE:**
- Detecta el idioma del usuario y responde en el mismo idioma
- Si el usuario escribe en sueco, responde en sueco
---
## HERRAMIENTAS
### getDrinks
Obtiene bebidas de nuestro menú.
- SIEMPRE llama a esta herramienta cuando el invitado pida recomendaciones
- Esta es tu ÚNICA fuente de información sobre bebidas
- Recomienda SOLO bebidas que existan en la respuesta
## IDENTIDAD
...
## FLUJO DE CONVERSACIÓN
...
## LIMITACIONES
...
"""Poner "REGLA CRÍTICAS - LEE PRIMERO" en la parte superior con formato en negrita señala importancia; "NUNCA DEBES" es más fuerte que "no" o "evita", y especificar exactamente qué decir cuando una bebida no está disponible elimina la ambigüedad; el modelo no tiene que averiguar cómo expresar una rechazo.
También añadí la regla de detección de idioma después de notar que el agente respondía en inglés incluso cuando yo preguntaba en sueco. Estas pueden parecer detalles pequeños, pero se suman a una mejor experiencia.
Pruebas
Después de cada iteración de la instrucción, hice las mismas pruebas para poder rastrear las mejoras más fácilmente que si solo preguntaba cosas al azar.
- Coincidencia directa: "Quiero un Negroni" (lo tenemos)
- Sin coincidencia: "¿Puedo tomar una Piña Colada?" (no lo tenemos)
- Solicitud vaga: "Algo refrescante con ginebra"
- Desafío: "¿Qué tal un Mojito con sandía?" (probando si inventa variaciones)
- Fuera de tema: "¿Cómo está el clima?" (debería mantenerse en personaje)
La instrucción final pasó todas las pruebas con gran éxito. Las versiones anteriores fallaban en algunos de los escenarios.
Al construir agentes IA, la instrucción del sistema es uno de nuestros controles principales. Es importante que seamos explícitos, repetitivos y pongamos las reglas más importantes donde el modelo las vea primero.
El Bucle Agente
Ya he mencionado el Bucle Agente varias veces, pero ¿qué es en detalle? ¿Cómo funciona realmente? Intentaré explicarlo.
Un usuario comienza preguntándole al agente una pregunta o dándole una orden directa—algo como "Quiero algo con ginebra" en el frontend de React. El frontend hace un POST al extremo /chat. API Gateway invoca la Lambda de streaming a través de /response-streaming-invocations, y Lambda Web Adapter inicia FastAPI, que maneja la solicitud. El manejador Lambda carga las herramientas MCP, inicializa el agente Strands que iniciará todo.
Strands comienza enviando el mensaje del usuario al LLM Nova 2 junto con la instrucción del sistema que definimos anteriormente, y cualquier historial de conversación de mensajes anteriores, obteniéndolo de AgentCore Memory. El modelo lee la instrucción del sistema, ve las reglas críticas sobre llamar SIEMPRE a getDrinks, y decide que necesita datos del menú antes de poder recomendar algo; esto hace que haga una llamada a la herramienta.
Strands recoge el resultado de la llamada a la herramienta y lo alimenta de vuelta al modelo.
Ahora el modelo tiene el menú real, filtra las bebidas a base de ginebra, considera las otras preferencias del invitado y crea una recomendación. Cada token ahora se transmite de vuelta a través de Strands, a través de la StreamingResponse de FastAPI, a través de API Gateway y al frontend, y AgentCore Memory guarda la conversación para la próxima vez.
Aquí está el núcleo del extremo de streaming.
async def stream_response():
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
tools=get_mcp_tools(),
session_manager=create_session_manager(session_id, actor_id),
)
async for event in agent.stream_async(message):
if isinstance(event, dict) and event.get("data"):
yield f"data: {json.dumps({'chunk': event['data'], 'sessionId': session_id})}\n\n"
yield f"data: {json.dumps({'done': True, 'sessionId': session_id})}\n\n"
return StreamingResponse(stream_response(), media_type="text/event-stream")El método stream_async es donde vive el bucle agente. Strands maneja el ida y vuelta necesario entre el modelo y las herramientas internamente. Desde la perspectiva de mi código, simplemente itero sobre eventos y produzco trozos de texto como Eventos Enviados al Servidor. Strands decide cuándo el modelo necesita otra llamada a la herramienta versus cuándo está listo para responder.

Costo
Para uso doméstico ocasional, esto es básicamente gratis.
| Componente | Costo |
|---|---|
| Bedrock Nova 2 Lite | ~$0.001/1K entrada, ~$0.002/1K tokens de salida |
| Lambda | ~$0.0000166 por GB-segundo |
| AgentCore Memory | Incluido con Bedrock |
| AgentCore Gateway | Incluido con Bedrock |
| Aurora DSQL | Pago por solicitud, mínimo para tráfico bajo |
Una conversación típica cuesta fracciones de centavo. Incluso con un grupo de 20 personas haciendo preguntas toda la noche, el total sería menos de un dólar.
Qué sigue
El Barman IA ahora está completo; las tres partes están hechas.
En la Parte 1 cubrí la base sin servidor con Aurora DSQL, APIs, autenticación y generación de imágenes impulsada por eventos. La Parte 2 añadió registro de invitados con códigos de invitación, JWTs autofirmados y actualizaciones en tiempo real de pedidos con AppSync Events. En esta última Parte 3 construí el agente de chat IA con Strands, herramientas MCP, AgentCore Memory y streaming de respuestas.
Ideas futuras incluyen expandir las herramientas, añadir inventario de ingredientes, quizás desde una imagen. Solo mi imaginación establece los límites.
Palabras Finales
Lo que comenzó como una solución para dejar de ser el menú humano en una fiesta en casa resultó ser una inmersión profunda en serverless, impulsado por eventos y IA. Cada parte vino con sus propios desafíos y problemas que fueron muy divertidos de resolver.
El código fuente completo está disponible en GitHub.
Visita mis otros posts en jimmydqv.com y sígueme en LinkedIn y X para más contenido sobre serverless.
¡Ahora ve a construir!