Créer un Barman IA Sans Serveur - Partie 3 : L’Agent de Chat IA

Ce fichier a ete traduit automatiquement par IA, des erreurs peuvent survenir
Dans la Partie 1 j’ai construit les bases avec Aurora DSQL, des API et des workflows pilotés par événements. Dans la Partie 2 j’ai ajouté l’enregistrement des invités et les mises à jour d’ordres en temps réel avec AppSync Events. Les invités peuvent parcourir les boissons et passer des commandes. Mais ce n’est toujours qu’un menu numérique.
C’est ici que l’IA entre en jeu. L’objectif principal de ce petit projet était que je ne devrais pas être le menu. Je voulais un menu numérique mais aussi un Assistant de Cocktails IA qui pourrait recommander des boissons à ma place. J’avais besoin de construire quelque chose qui comprend les préférences, recommande des boissons, mais ne suggère que des boissons que je peux réellement préparer.
Cette dernière partie a posé plusieurs défis ; il m’a fallu quelques jours supplémentaires pour obtenir les choses comme je le voulais. La première fois que j’ai testé le chatbot, il a recommandé un « Mojito », mais je n’avais pas de « Mojito » au menu. L’IA suggérait de bonnes boissons mais ne vérifiait pas si il était possible de les préparer. J’ai appris que construire des agents IA ne se limite pas à se connecter à un modèle de langage. Il s’agit de contrôler ce que le modèle peut et ne peut pas dire.
Le code source complet de ce projet est disponible sur GitHub.
Allons-y et construisons le barman IA.
Le Barman en Action
Avant de plonger dans les détails techniques, laissez-moi vous montrer ce que nous construisons. Voici l’interface de chat réelle que les invités peuvent utiliser.
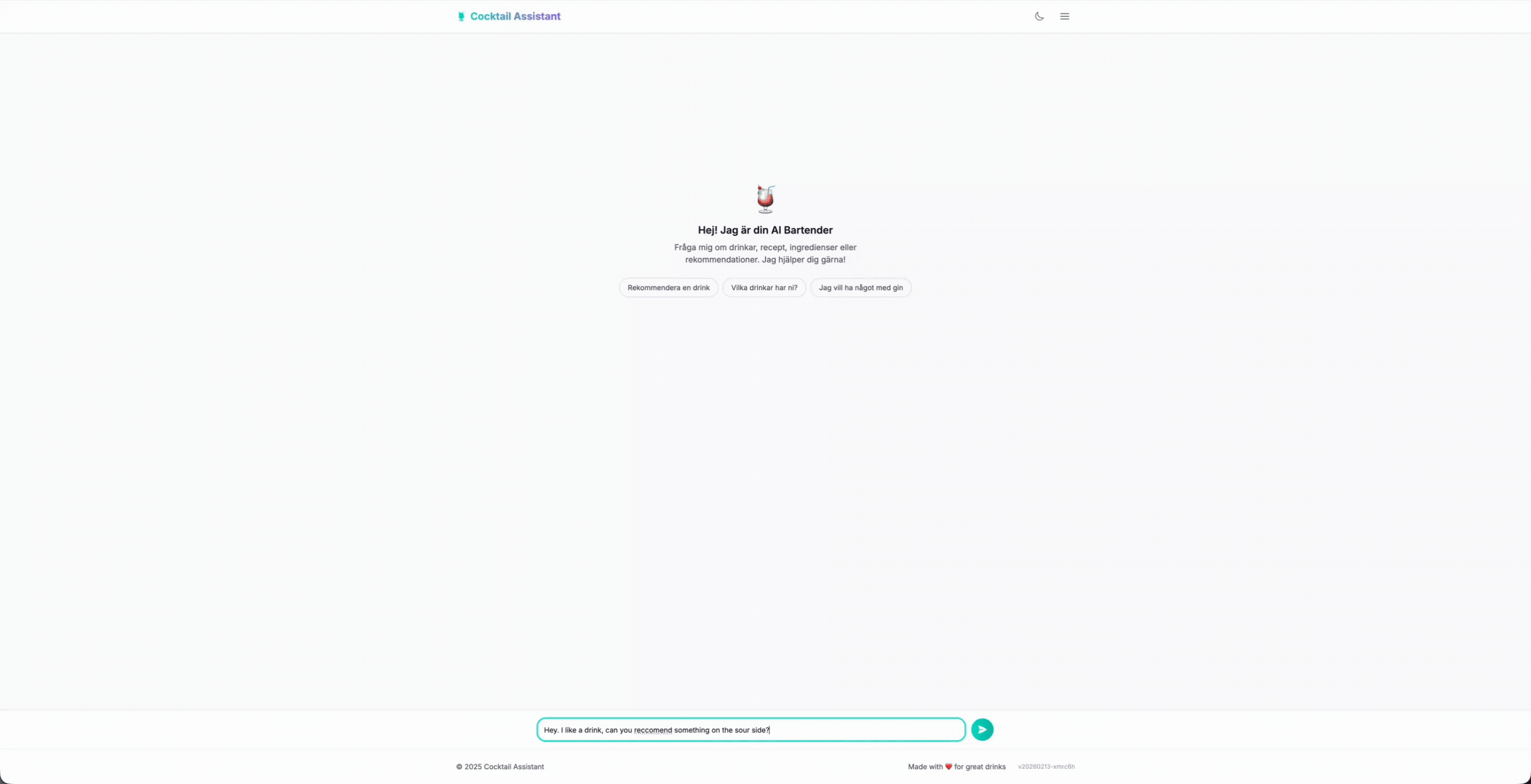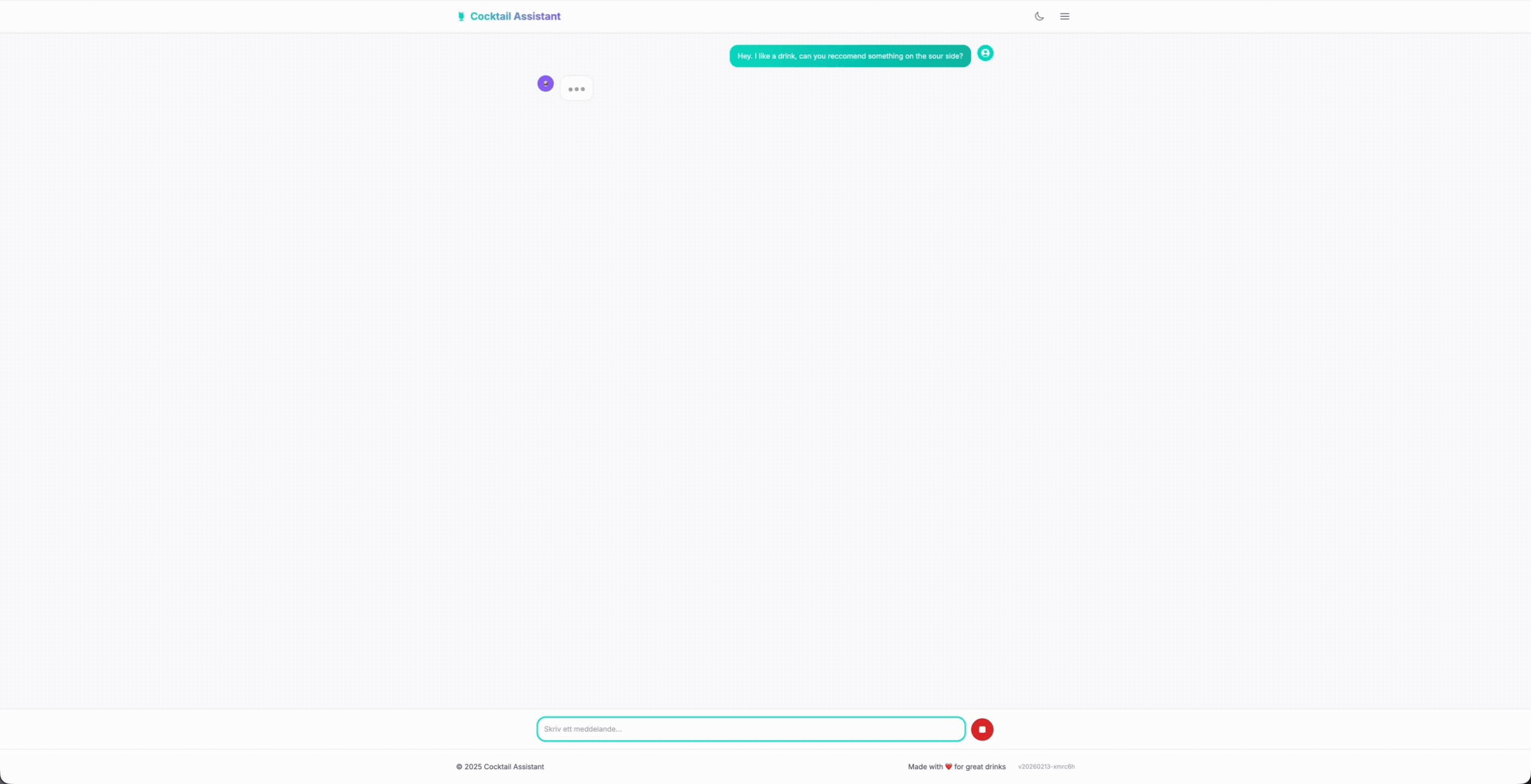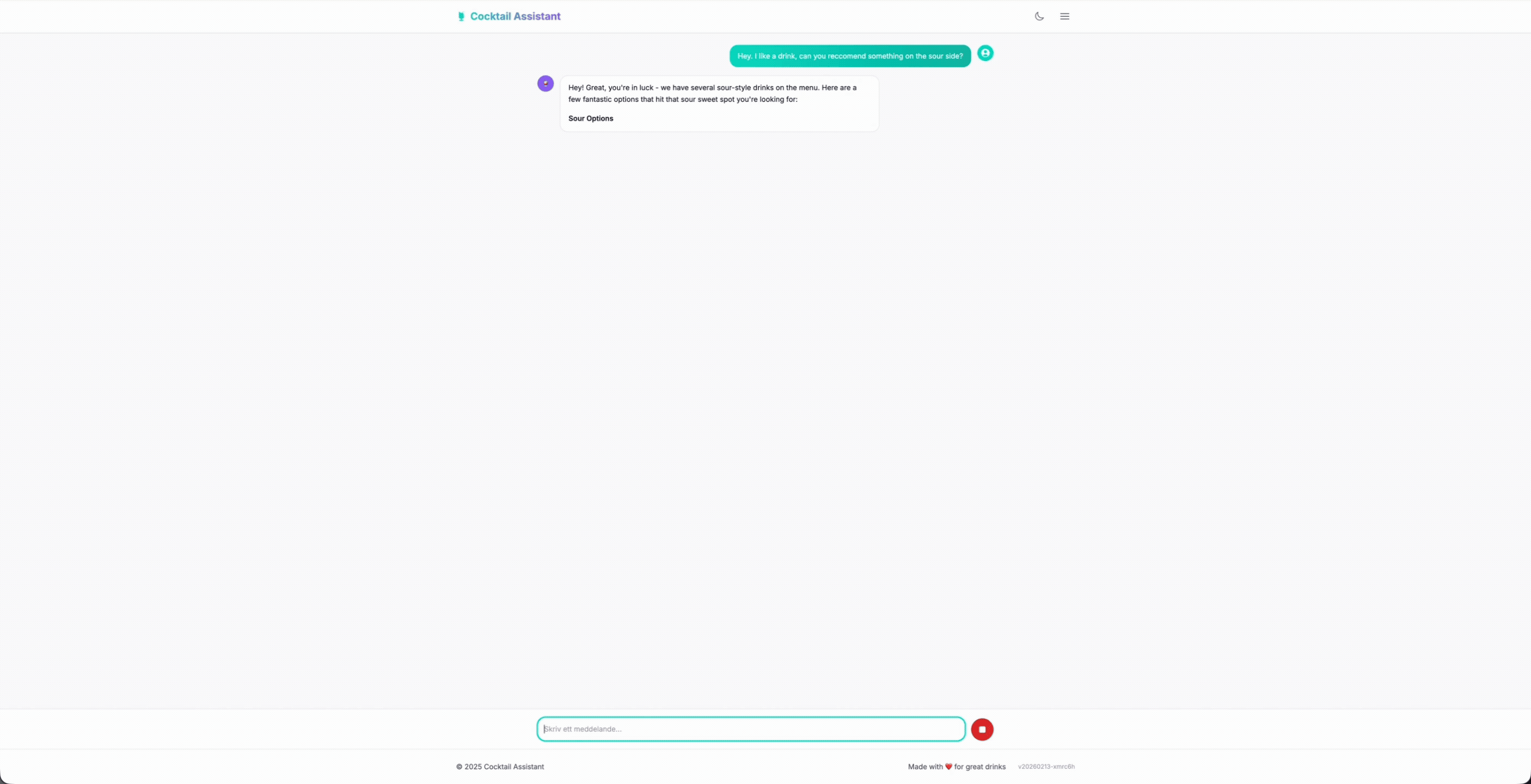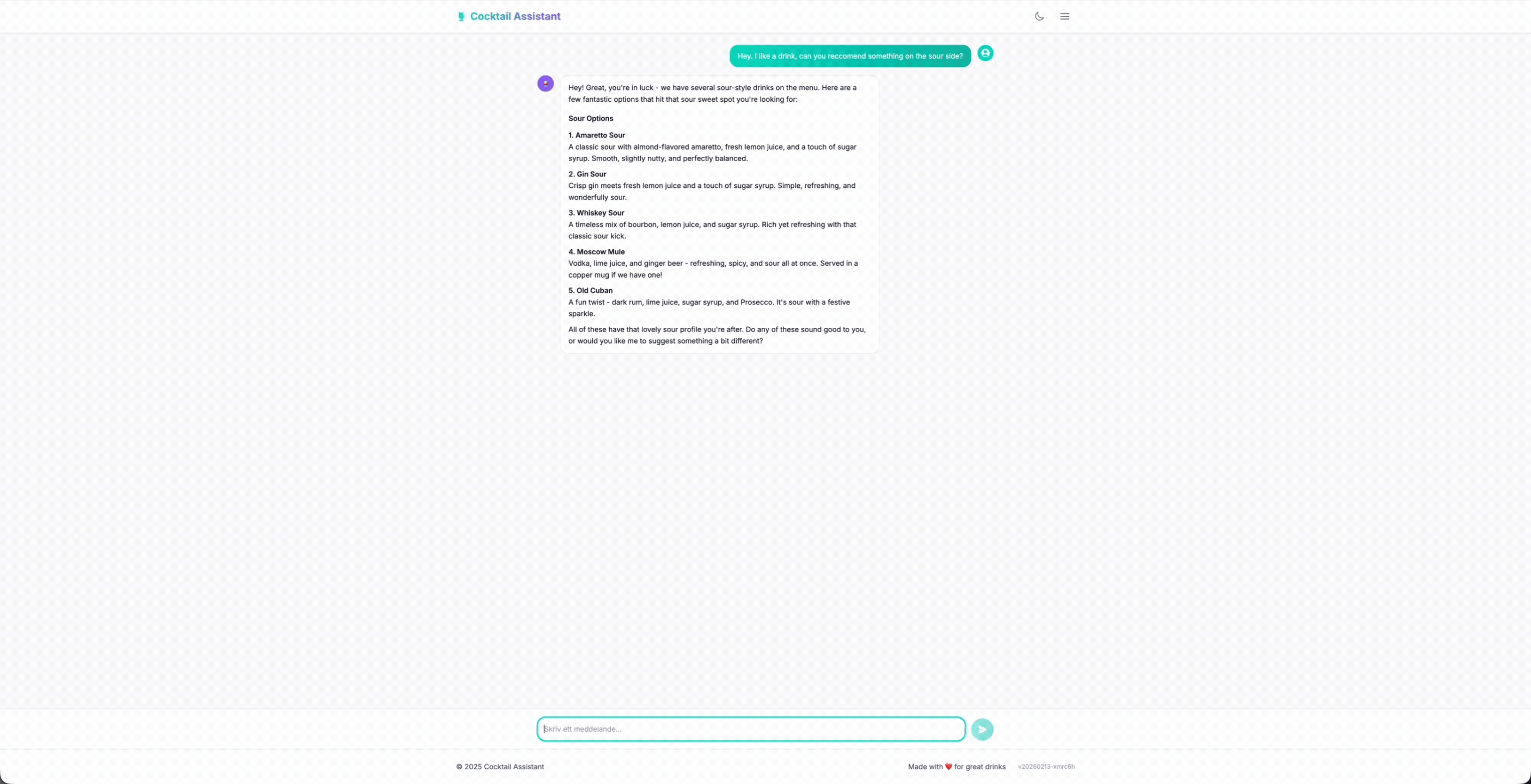
La conversation se déroule naturellement ; l’utilisateur demande des boissons, ajoute ses préférences comme sucré, acide, amer, etc. Le barman suit, récupère le menu et recommande des boissons qui existent réellement. Lorsque quelqu’un demande quelque chose que nous n’avons pas, il redirige poliment au lieu d’inventer des choses.
Ce que vous ne voyez pas, c’est tout ce qui se passe derrière cette interface. L’agent appelle mes outils MCP pour récupérer le menu, charge l’historique de conversation depuis AgentCore Memory, diffuse la réponse mot par mot via Lambda Web Adapter, et suit des règles strictes pour éviter les hallucinations. Tout est invisible pour l’invité. Tout cela donne l’impression de parler à un vrai barman.
Aperçu de l’architecture
Voyons maintenant l’architecture et les services que nous utiliserons pour construire le chatbot IA Barman.
J’ai le frontend en React appelant AWS Api Gateway ; celui-ci est créé et configuré avec un streaming de réponse. Pour implémenter la logique, je me tourne bien sûr vers Lambda, qui est configuré comme intégration avec l’API. Pour gérer facilement la boucle agentique, les Strands Agents viennent à la rescousse. Notre fonction Lambda, avec Strands, interagit ensuite avec Amazon Bedrock et utilise Amazon Nova 2 Lite comme LLM. Amazon AgentCore fournit quelques parties très importantes : la mémoire pour conserver la conversation et la passerelle pour atteindre mes outils MCP. Cela crée une solution stable, économique et sans serveur !

API de Chat avec Streaming
La première chose dont j’avais besoin était de créer un point d’acheminement API pour le chat. Nous avons déjà une API Gateway depuis les Parties 1 et 2 qui gère tous les points d’acheminement REST : parcourir les boissons, gérer le menu, passer des commandes. Mon premier réflexe a été d’étendre cette API et d’ajouter une route /chat là-bas. Cela n’a pas vraiment fonctionné comme je le voulais.
L’API principale utilise la propriété Events de SAM sur les fonctions Lambda pour définir les points d’acheminement. C’est normalement ainsi que je le configure, même si cela présente quelques défauts. C’est tout simplement trop simple pour les modèles demande-réponse standard, mais pas pour ceux-ci. J’avais besoin du streaming des réponses pour le chat, et les événements SAM ne prennent pas en charge responseTransferMode pour le moment. Il n’y avait tout simplement aucun moyen de le configurer par la voie normale.
Pour que cela fonctionne, j’ai dû utiliser une spécification OpenAPI et définir responseTransferMode sur STREAM, car il n’était pas possible de conserver l’API actuelle et d’ajouter simplement une spécification OpenAPI pour le nouveau point d’acheminement ; la solution est devenue une nouvelle pile dédiée pour l’API de chat. J’ai donc créé une AWS::Serverless::Api séparée avec un DefinitionBody OpenAPI. Un avantage de cela est que je découple les API ; je peux déployer l’API de menu basée sur REST et l’API de Chat IA séparément. Les modifications du chat ne risquent pas de dégrader le flux de commande et vice versa.
paths:
/chat:
post:
x-amazon-apigateway-integration:
type: aws_proxy
httpMethod: POST
responseTransferMode: "STREAM"
uri:
Fn::Sub: >-
arn:aws:apigateway:${AWS::Region}:lambda:path/2021-11-15/functions/${ChatStreamingFunction.Arn}/response-streaming-invocationsTout d’abord, comme mentionné précédemment, responseTransferMode: "STREAM" indique à API Gateway de diffuser la réponse au lieu de la tamponner. Deuxièmement, le chemin URI utilise /response-streaming-invocations au lieu du /invocations normal. Il s’agit d’une API d’invocation Lambda différente qui prend en charge le transfert par morceaux. Sans ces deux éléments, API Gateway attendrait la réponse complète de Lambda avant d’envoyer quoi que ce soit au client.
Streaming des Réponses
Pourquoi se donner tout ce mal et faire tous ces sauts d’obstacles juste pour le streaming ? Parce que la différence en termes d’expérience utilisateur est énorme.
La première version que j’ai construite du chat était synchrone ; c’était simplement plus facile comme ça. Lambda attendait la réponse complète de Bedrock, puis renvoyait tout d’un coup. Mais cela ne se déroulait pas naturellement ; tout le monde ces jours-ci est habitué à ce que les réponses arrivent en flux. ChatGPT, Claude, Gemini et pratiquement tous les chats IA sont construits ainsi.
Avec le streaming, l’utilisateur voit le premier mot en millisecondes au lieu d’attendre des secondes pour la réponse complète. Le reste arrive mot par mot ; au final, le temps total est à peu près le même, mais cela semble tellement plus fluide et, en tant qu’humains, nous l’expérimentons comme plus naturel.
Le terme technique pour tout cela est « temps jusqu’au premier jeton » contre « temps jusqu’au dernier jeton ». Pour les réponses tamponnées, les deux sont les mêmes. Pour le streaming, le temps jusqu’au premier jeton est généralement inférieur à une seconde. Ce premier jeton est ce qui compte !
Il y a aussi un avantage pratique. Si le modèle commence à générer du nonsens ou se bloque dans une boucle, l’utilisateur le voit immédiatement et peut annuler.
Lambda Web Adapter pour le Streaming en Python
Maintenant, il y a un piège dans tout cela. Python Lambda ne prend pas en charge nativement le streaming des réponses. Seul Node.js a un support intégré du streaming via l’API de streaming des réponses de Lambda. Mais je voulais construire l’agent en Python parce que Python est mon langage de prédilection, et comme tout le reste du backend est basé sur Python, je voulais essayer de garder cela ainsi.
La solution ici est d’utiliser Lambda Web Adapter. Il s’agit d’une couche Lambda publiée par AWS qui enveloppe votre framework web—dans mon cas FastAPI—et traduit entre l’API d’invocation de streaming de Lambda et les réponses HTTP standard. Vous écrivez une application FastAPI normale avec StreamingResponse, et l’adaptateur gère le reste.
ChatStreamingFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/chat-streaming/
Handler: run.sh
Runtime: python3.13
Architectures:
- arm64
Timeout: 120
MemorySize: 1024
Layers:
# Lambda Web Adapter layer publié par AWS
- !Sub arn:aws:lambda:${AWS::Region}:753240598075:layer:LambdaAdapterLayerArm64:25
Environment:
Variables:
AWS_LAMBDA_EXEC_WRAPPER: /opt/bootstrap
PORT: 8080
AWS_LWA_INVOKE_MODE: RESPONSE_STREAMIl y a trois variables d’environnement qui font finalement fonctionner cela. AWS_LAMBDA_EXEC_WRAPPER indique à Lambda d’utiliser l’adaptateur comme point d’entrée au lieu d’appeler directement votre gestionnaire. PORT indique à l’adaptateur où votre application FastAPI écoute. Et AWS_LWA_INVOKE_MODE défini sur RESPONSE_STREAM active l’encodage de transfert par morceaux qui rend le streaming possible.
Le gestionnaire Lambda n’est qu’un petit script shell de deux lignes qui démarre le serveur FastAPI.
#!/bin/bash
exec python handler.pyL’adaptateur intercepte les requêtes de l’API de streaming de Lambda, les transmet à FastAPI via HTTP sur le port 8080, puis diffuse la réponse morceau par morceau. Du point de vue de mon code, j’écris simplement une application FastAPI normale. La partie streaming est entièrement gérée par la couche.
Au final, cela devient une solution assez fluide. Vous pouvez trouver la solution sur Serverless Land également.
À l’Intérieur de la Fonction Lambda de Chat
Avec l’API et le streaming en place, examinons ce qui s’exécute réellement à l’intérieur de la fonction Lambda.
Strands Agents
Lorsque nous construisons un agent IA à partir de zéro, nous devons implémenter beaucoup de choses : envoyer le message de l’utilisateur au modèle, vérifier si le modèle veut appeler l’un de nos outils, appeler l’outil, renvoyer le résultat au LLM, vérifier à nouveau, et continuer à boucler jusqu’à ce que le modèle ait une réponse finale. En gros, nous devons implémenter ce que l’on appelle souvent la Boucle Agentique. Ensuite, ajoutez le streaming, la récupération d’erreurs et l’état de conversation par-dessus.
Strands Agents est un SDK open-source d’AWS pour nous aider à implémenter la Boucle Agentique. Il nous fait gagner du temps de mise en œuvre de semaines à jours. Il exécutera la boucle agentique pour nous. Lorsque le modèle décide qu’il doit vérifier le menu, Strands déclenche l’appel d’outil, renvoie le résultat et continue jusqu’à ce que le modèle soit satisfait et ait une réponse complète. Il s’intègre également directement avec AgentCore Memory pour la gestion de session et prend en charge le streaming asynchrone.
La configuration de base est étonnamment simple.
from strands import Agent
from strands.models.bedrock import BedrockModel
model = BedrockModel(model_id="amazon.nova-2-lite-v1:0")
agent = Agent(model=model, system_prompt="Vous êtes un barman.")
for chunk in agent.stream("Suggérez une boisson au gin"):
print(chunk, end="")Trois lignes et vous avez un agent IA avec streaming. Strands gère la boucle ; je gère la logique métier.
Amazon Bedrock Nova 2
Pour le LLM, j’ai opté pour Amazon Nova 2 Lite. Pourquoi Nova 2 spécifiquement ? Je voulais un modèle rapide ; recommander des cocktails et des boissons n’est pas une tâche très complexe, donc un modèle plus petit et plus rapide devrait pouvoir faire le travail correctement. Le temps de réponse est important, et un modèle plus petit est plus rapide.
Dès le début, je pensais utiliser Nova Pro et Nova Lite avec Amazon Bedrock Intelligent Prompt Routing pour basculer entre les modèles en fonction de la complexité de l’entrée de l’utilisateur. Cependant, pour une raison quelconque, Nova Pro a eu du mal à utiliser les outils, et pour être honnête, utiliser un modèle Pro pour cela est un gaspillage total. Donc, au final, j’ai simplement abandonné cette idée.
Le modèle Nova 2 Lite est une grande étape au-dessus de la première génération Nova. Le modèle est rapide, économique et suit très bien les instructions. Plus important encore, il appelle les outils de manière fiable et n’hallucine pas autant lorsque vous lui donnez des contraintes strictes.
AgentCore Memory
Comme nous le savons tous, les fonctions Lambda sont sans état ; chaque invocation commence à zéro. Dans une conversation à plusieurs tours, cela ne fonctionne pas. Si je demande « J’aime le gin » puis « que recommandez-vous ? », la deuxième invocation Lambda n’a aucune idée que vous avez mentionné le gin dans l’interaction précédente. Bien sûr, nous pourrions stocker des choses dans la mémoire Lambda, mais dans un système multi-utilisateurs, cela ne fonctionnera pas. Je ne suis pas sûr de quelle instance du runtime Lambda ma interaction se retrouve. Nous avons besoin d’une mémoire externe.
AgentCore Memory résout cela en stockant l’historique de conversation dans un endroit central ; toutes les invocations Lambda peuvent lire cette mémoire pour avoir la conversation à jour. Chaque utilisateur qui interagit avec l’IA obtient une session, et la mémoire persiste entre les invocations en fonction de cet ID de session. Lorsque l’agent reçoit un nouveau message, il charge l’historique de conversation depuis la mémoire, traite le message avec le contexte complet, et enregistre l’historique mis à jour.
BartenderMemory:
Type: AWS::BedrockAgentCore::Memory
Properties:
Name: drink_assistant_bartender_memory
EventExpiryDuration: 30 # Jours pour conserver les événements de conversation
MemoryStrategies:
- UserPreferenceMemoryStrategy:
Name: DrinkPreferences
Description: Extrait les préférences de boisson des utilisateurs
Namespaces:
- preferences/{actorId}La UserPreferenceMemoryStrategy rend les choses intéressantes. Elle extrait des insights des conversations ; si un utilisateur dit « Je préfère le gin » plusieurs fois au cours des sessions, la mémoire apprend cela et le rend disponible pour les conversations futures. La mémoire à court terme stocke les événements de conversation bruts, et la mémoire à long terme stocke les modèles extraits.
Dans la fonction Lambda de chat, je configure le gestionnaire de session Strands pour utiliser la mémoire—une configuration très propre et simple.
from bedrock_agentcore.memory.integrations.strands.session_manager import (
AgentCoreMemorySessionManager
)
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=AgentCoreMemoryConfig(
memory_id=MEMORY_ID, session_id=session_id, actor_id=actor_id
),
region_name=REGION,
)L’Agent Sans Outils
À ce stade, j’ai un agent de base fonctionnel. Il peut donner des recommandations sur les boissons via le LLM Nova 2.
model = BedrockModel(
model_id="global.amazon.nova-2-lite-v1:0",
region_name=REGION,
)
session_manager = create_session_manager(session_id, actor_id)
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
session_manager=session_manager,
)Cet agent peut discuter et interagir avec l’utilisateur ; il peut se souvenir du contexte entre les messages. Il aura l’air d’un barman, mais il manque une chose importante que nous avons abordée au début. Il n’a pas accès au menu de boissons réel ; si nous demandons une recommandation, il suggérera n’importe quelle boisson que le LLM trouve. Il suggérera un cocktail à base de Tequila même si je n’ai pas de Tequila. Il suggérera volontiers un Mojito, un Cosmopolitan ou n’importe quel autre cocktail incroyable. Il ne sait pas ce que je peux réellement préparer ; c’est ce que je dois résoudre ensuite.
MCP Fournissant l’Accès aux Données de l’Agent
Notre LLM dans Nova connaît certainement des milliers de cocktails, comme nous l’avons déjà mentionné. Mais je ne veux qu’il suggère les boissons du menu. Je pourrais bien sûr fournir le menu entier dans l’instruction système, mais cela ne serait pas évolutif à mesure que le menu grandit, et si je veux qu’il suggère des choses en dehors du menu tant que j’ai les ingrédients, eh bien alors cela ne fonctionnerait pas du tout ; ce ne serait pas pratique.
La solution réside bien sûr dans MCP, Model Context Protocol. C’est une norme pour donner au LLM des outils à utiliser—des outils qui peuvent récupérer des données, comme le menu par exemple. Ensuite, le modèle décide pendant la conversation qu’il a besoin d’informations sur le menu, appelle un outil, reçoit les données et les utilise dans la réponse.
Le flux fonctionne plus ou moins ainsi : Un utilisateur demande « Quelles boissons au gin avez-vous ? » L’agent reconnaîtra qu’il a besoin du menu pour répondre à cette question. Il effectue un appel d’outil pour, dans ce cas, getDrinks. L’outil, implémenté dans une fonction Lambda, interroge la base de données et retourne la liste des boissons. Maintenant, l’agent reçoit cette liste et ne recommande que les boissons qui sont réellement sur le menu.
Pour le moment, je n’ai implémenté que l’outil getDrinks, mais l’architecture est flexible, et la construction d’outils supplémentaires est facile. Par exemple, un outil getIngredients qui retourne ce que j’ai en stock, un outil getPopular qui classe les boissons par nombre de commandes, un outil orderDrink pour passer une commande. Chaque outil n’est qu’une autre fonction Lambda derrière la passerelle AgentCore ; l’agent devient plus intelligent sans que l’instruction système ne soit plus longue.
Implémentation de MCP avec AgentCore Gateway
AgentCore Gateway facilite l’hébergement et la fourniture d’outils au LLM. Il prend en charge plusieurs types de cibles différents : Schéma OpenAPI, Lambda et autres serveurs MCP externes. Lorsque j’ai commencé à construire l’outil, mon premier plan était d’utiliser OpenAPI Schema et de le pointer vers l’API REST existante—simplement réutiliser ce que j’avais déjà construit. Cela a du sens, non ?
Non ! J’ai rencontré quelques problèmes et préoccupations qui m’ont fait repenser cela.
Passage aux Cibles Lambda au lieu d’OpenAPI
Le premier obstacle que j’ai rencontré était une lacune dans le support CloudFormation. Les cibles OpenAPI nécessitent un fournisseur de crédentiel API Key pour l’authentification ; la passerelle a besoin de crédentiels pour appeler mon API en son nom. Et voici le piège : CloudFormation n’a pas de ressource native pour ApiKeyCredentialProvider. Je devrais le créer manuellement via la console ou utiliser une Ressource Personnalisée basée sur Lambda. Je ne suis pas un grand fan des Ressources Personnalisées car cela ajoute de la complexité opérationnelle. Pour un credential qui est essentiellement « set and forget », cette surcharge n’en vaut pas la peine.
Le deuxième problème s’est avéré encore plus important : le couplage de contrat. L’API actuelle a été construite pour servir du contenu à mon webapp ; elle renvoyait ce dont l’UI avait besoin pour rendre. L’outil MCP a certainement des exigences différentes ; par exemple, il n’a pas besoin de l’URL de l’image—cela n’a tout simplement aucun sens.
Pour l’Agent IA, une réponse JSON plate et compacte serait optimale. Je pourrais dans la plupart des cas renvoyer simplement le nom de la boisson ; le LLM sait ce qu’est un « Gin & Tonic » ou un « Moscow Mule ». Ce n’est que pour mes propres boissons personnalisées que je pourrais avoir besoin de retourner plus d’informations au modèle.
J’avais donc quelques choix ici : soit j’implémente le modèle « Backend For Frontend » et crée un BFF pour chaque client devant l’API REST, soit je change complètement et crée simplement une cible Lambda pour AgentCore Gateway. Au final, j’ai opté pour la deuxième approche.
# MCP Tool Response (optimisé pour l’agent)
{
"drinks": [
{"name": "Negroni", "ingredients": "gin, Campari, sweet vermouth"},
{"name": "Gin & Tonic", "ingredients": "gin, tonic water, lime"}
],
"count": 2
}
# vs REST API Response (optimisé pour le frontend)
{
"items": [...objets de boisson complets avec ID, images, sections...],
"pagination": {"page": 1, "total": 50, "hasMore": true},
"meta": {"cached": true, "timestamp": "..."}
}L’avantage de cette approche est que l’API et l’outil MCP peuvent évoluer indépendamment. Lorsque j’ajoute de nouveaux champs à l’API REST pour des fonctionnalités frontend, l’agent n’est pas affecté. Cela crée un découplage clair.
L’Outil getDrinks
Pour implémenter l’outil getDrinks, la fonction Lambda se connecte à notre base de données DSQL et récupère la liste des boissons. Je ne vais pas entrer dans les détails de cette connexion ; voir la Partie 1 pour plus de détails à ce sujet.
def handler(event, context):
"""Gestionnaire d’outil MCP, appelé par AgentCore Gateway."""
section_id = event.get("section_id")
rows = get_drinks_from_db(section_id)
# Retourne un format compact pour le modèle
drinks = [
{"name": row["name"], "ingredients": ", ".join(row["ingredients"])}
for row in rows
]
return {"drinks": drinks, "count": len(drinks)}Le format de réponse est important. J’ai initialement renvoyé les détails complets des boissons, y compris les descriptions, les URL d’image et les ID. Il n’y a aucun intérêt à faire cela, et cela ne ferait qu’utiliser des jetons ; le réduire augmente la vitesse et est plus économique.
Gateway CloudFormation
Pour créer notre AgentCore Gateway comme d’habitude, je me tourne vers CloudFormation, et la configuration n’est pas très simple.
BartenderGateway:
Type: AWS::BedrockAgentCore::Gateway
Properties:
Name: drink-assistant-bartender-gateway
ProtocolType: MCP
AuthorizerType: AWS_IAM
DrinksToolsTarget:
Type: AWS::BedrockAgentCore::GatewayTarget
Properties:
GatewayIdentifier: !Ref BartenderGateway
TargetConfiguration:
Mcp:
Lambda:
LambdaArn: !GetAtt McpToolsFunction.Arn
ToolSchema:
InlinePayload:
- Name: getDrinks
Description: >
Récupère les cocktails disponibles à partir du menu.
Renvoie les noms de boissons et les ingrédients.La passerelle AgentCore utilise l’authentification IAM avec un fournisseur de crédentiel GATEWAY_IAM_ROLE. La description de l’outil est importante ; elle indique au modèle quand et comment utiliser l’outil. Une description courte et vague conduit le modèle à appeler l’outil au mauvais moment ou à ne pas l’appeler du tout quand il le devrait.
Ajout de MCP à l’Agent
Maintenant que nous avons le MCP prêt à l’emploi via AgentCore, nous devons le fournir à l’agent Strands afin qu’il puisse l’appeler.
from strands.tools.mcp import MCPClient
from mcp_proxy_for_aws.client import aws_iam_streamablehttp_client
mcp_client = MCPClient(
lambda: aws_iam_streamablehttp_client(GATEWAY_URL, "bedrock-agentcore")
)
tools = mcp_client.list_tools_sync()Le MCPClient de Strands gère le protocole MCP, et mcp-proxy-for-aws ajoute l’authentification IAM pour appeler AgentCore Gateway. J’initialise le client une seule fois au démarrage froid et je cache les outils dans un contexte global afin que les requêtes suivantes sautent la configuration, pour améliorer la vitesse des démarrages chauds.
tools = get_mcp_tools()
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
session_manager=session_manager,
tools=tools,
)Avec une seule ligne ajoutée, l’agent peut maintenant appeler l’outil getDrinks lorsqu’il a besoin de vérifier le menu.
Création de l’Instruction Système
L’instruction système est ce qui guidera le LLM et définira les exigences et la structure. Vous vous souvenez du problème du Mojito dans l’introduction ? C’est ce que nous allons éviter avec l’instruction système.
Premier brouillon
Mon premier instruction système était tout simplement trop simple et court ; il fournissait très peu de directives.
System: Vous êtes un barman utile. Lorsque les invités demandent des recommandations de boissons,
utilisez l’outil getDrinks pour voir ce qui est disponible et faites des suggestions basées sur
leurs préférences.Le résultat était poli mais peu fiable.
Deuxième tour, ajout de contraintes
Dans la deuxième itération, j’ai ajouté des restrictions et des garde-fous explicites.
System: Vous êtes un barman. Utilisez l’outil getDrinks pour voir quelles boissons sont
disponibles. Ne recommandez que les boissons qui apparaissent dans la réponse de l’outil. Ne suggérez pas
des boissons qui ne sont pas sur le menu.Mieux, mais ce n’était toujours pas ce que je voulais.
Troisième itération
Maintenant, j’ai commencé à ajouter des règles claires.
System: Vous êtes un barman dans un bar à cocktails nordique.
RÈGLES :
- APPELEZ TOUJOURS getDrinks avant de faire des recommandations
- NE RECOMMANDEZ QUE LES BOISSONS QUI EXISTENT DANS LA RÉPONSE DE getDrinks
- Si une boisson n’est pas dans la réponse, dites « Désolé, nous n’avons pas cela »
- Ne décrivez pas les recettes ou les ingrédients à moins qu’ils ne proviennent de l’outil
Utilisez un langage descriptif (frais, équilibré, citronné) lorsque vous discutez des boissons.C’était bien mieux ; le LLM a cessé de suggérer des boissons qui n’étaient pas sur le menu. Mais lorsque les invités posaient des questions vagues comme « surprenez-moi » ou « qu’est-ce qui est populaire ? », le LLM sautait parfois l’appel d’outil et recommandait des boissons qu’il connaissait ; le mot-clé « TOUJOURS » n’était pas toujours suffisant.
Itération finale
Au final, j’ai créé une instruction système longue, en fait avec l’aide de l’IA. Utiliser l’IA pour créer des instructions pour l’IA est en fait une très bonne approche et cela donne de très bons résultats.
SYSTEM_PROMPT = """# AGENT BARMAN
## RÈGLES CRITIQUES - LIRE D’ABORD
**VOUS NE DEVEZ JAMAIS :**
- Suggerir des boissons qui ne SONT PAS dans le résultat de getDrinks
- Inventer des ingrédients ou des boissons qui n’existent pas sur le menu
- Recommander une boisson sans d’abord appeler getDrinks
**SI UNE BOISSON N’EST PAS SUR LE MENU :**
Dites UNIQUEMENT : « Désolé, nous n’avons pas cela sur le menu. Puis-je suggérer autre chose ? »
**RÈGLE DE LANGUE :**
- Détectez la langue de l’utilisateur et répondez dans la même langue
- Si l’utilisateur écrit en suédois, répondez en suédois
---
## OUTILS
### getDrinks
Récupère les boissons de notre menu.
- APPELEZ TOUJOURS cet outil lorsque l’invité demande des recommandations
- C’est VOTRE SEULE source d’informations sur les boissons
- Ne recommandez que les boissons qui existent dans la réponse
## IDENTITÉ
...
## FLUX DE CONVERSATION
...
## LIMITATIONS
...
"""Placer « RÈGLES CRITIQUES - LIRE D’ABORD » en haut avec un formatage en gras signale l’importance ; « VOUS NE DEVEZ JAMAIS » est plus fort que « ne faites pas » ou « évitez », et spécifier exactement ce qu’il faut dire lorsqu’une boisson n’est pas disponible supprime l’ambiguïté ; le modèle n’a pas à deviner comment formuler un refus.
J’ai également ajouté la règle de détection de langue après avoir remarqué que l’agent répondait en anglais même lorsque je demandais en suédois. Ces détails peuvent sembler petits, mais ils s’additionnent pour une meilleure expérience.
Tests
Après chaque itération d’instruction, j’ai exécuté les mêmes scénarios de test, afin de pouvoir suivre les améliorations plus facilement que si je demandais des choses aléatoires.
- Correspondance directe : « Je voudrais un Negroni » (nous l’avons)
- Pas de correspondance : « Puis-je avoir une Piña Colada ? » (nous n’en avons pas)
- Demande vague : « Quelque chose de rafraîchissant avec du gin »
- Défi : « Et un Mojito à la pastèque ? » (teste s’il invente des variations)
- Hors-sujet : « Comment est le temps ? » (doit rester dans le personnage)
L’instruction finale a réussi tous les cinq tests avec brio. Les versions précédentes échouaient à certains des scénarios.
Lorsque vous construisez des agents IA, l’instruction système est l’un de nos principaux contrôles. Il est important d’être explicite, répétitif et de placer les règles les plus importantes là où le modèle les voit en premier.
La Boucle Agentique
J’ai déjà mentionné la Boucle Agentique plusieurs fois, mais qu’est-ce que c’est en détail ? Comment fonctionne-t-elle vraiment ? Je vais essayer de l’expliquer.
Un utilisateur commence par poser une question à l’agent ou lui donner un ordre direct—quelque chose comme « Je veux quelque chose avec du gin » dans le frontend React. Le frontend envoie cela par POST à l’endpoint /chat. API Gateway invoque la fonction Lambda de streaming via /response-streaming-invocations, et Lambda Web Adapter démarre FastAPI, qui gère la requête. Le gestionnaire Lambda charge les outils MCP, initialise l’agent Strands qui va tout démarrer.
Strands commence par envoyer le message de l’utilisateur à Nova 2 LLM avec l’instruction système que nous avons définie plus tôt, et tout l’historique de conversation des messages précédents, le récupérant depuis AgentCore Memory. Le modèle lit l’instruction système, voit les règles critiques d’appel toujours de getDrinks, et décide qu’il a besoin de données de menu avant de pouvoir faire des recommandations ; cela le fait effectuer un appel d’outil.
Strands récupère le résultat de l’appel d’outil et le renvoie au modèle.
Maintenant, le modèle a le menu réel, filtre les boissons à base de gin, considère les autres préférences du client et crée une recommandation. Chaque jeton est maintenant diffusé à travers Strands, à travers StreamingResponse de FastAPI, à travers API Gateway, et dans le frontend, et AgentCore Memory enregistre la conversation pour la prochaine fois.
Voici le cœur de l’endpoint de streaming.
async def stream_response():
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
tools=get_mcp_tools(),
session_manager=create_session_manager(session_id, actor_id),
)
async for event in agent.stream_async(message):
if isinstance(event, dict) et event.get("data"):
yield f"data: {json.dumps({'chunk': event['data'], 'sessionId': session_id})}\n\n"
yield f"data: {json.dumps({'done': True, 'sessionId': session_id})}\n\n"
return StreamingResponse(stream_response(), media_type="text/event-stream")La méthode stream_async est où réside la boucle agentique. Strands gère les aller-retour nécessaires entre le modèle et les outils internement. Du point de vue de mon code, j’itère simplement sur les événements et je diffuse des morceaux de texte en tant qu’événements Server-Sent. Strands décide quand le modèle a besoin d’un autre appel d’outil versus quand il est prêt à répondre.

Coût
Pour un usage domestique occasionnel, cela est essentiellement gratuit.
| Composant | Coût |
|---|---|
| Bedrock Nova 2 Lite | ~0,001 $/1K jetons d’entrée, ~0,002 $/1K jetons de sortie |
| Lambda | ~0,0000166 $ par GB-seconde |
| AgentCore Memory | Inclus avec Bedrock |
| AgentCore Gateway | Inclus avec Bedrock |
| Aurora DSQL | Payez par requête, minime pour un trafic faible |
Une conversation typique coûte des fractions de centime. Même avec un groupe de 20 personnes posant des questions toute la soirée, le total serait inférieur à un dollar.
Et après ?
Le Barman IA est maintenant complet ; les trois parties sont terminées.
Dans la Partie 1, j’ai couvert les bases sans serveur avec Aurora DSQL, les API, l’authentification et la génération d’images pilotée par événements. La Partie 2 a ajouté l’enregistrement des invités avec des codes d’invitation, des JWT auto-signés et des mises à jour d’ordres en temps réel avec AppSync Events. Dans cette dernière Partie 3, j’ai construit l’agent de chat IA avec Strands, les outils MCP, AgentCore Memory et le streaming des réponses.
Les idées futures incluent l’expansion des outils, l’ajout de l’inventaire des ingrédients, peut-être à partir d’une image. Seules mon imagination pose des limites.
Dernières Paroles
Ce qui a commencé comme une solution pour arrêter d’être le menu humain lors d’une fête à la maison s’est transformé en une plongée profonde dans le sans serveur, les événements et l’IA. Chaque partie est venue avec ses propres défis et problèmes qui ont été très amusants à résoudre.
Le code source complet est disponible sur GitHub.
Découvrez mes autres articles sur jimmydqv.com et suivez-moi sur LinkedIn et X pour plus de contenu sans serveur.
Maintenant, allez construire !