Construindo um Bartender IA Sem Servidor - Parte 3: O Agente de Chat de IA

Este arquivo foi traduzido automaticamente por IA, erros podem ocorrer
Na Parte 1 eu construí a base com Aurora DSQL, APIs e fluxos de trabalho orientados a eventos. Na Parte 2 adicionei o registro de convidados e atualizações ao vivo de pedidos com AppSync Events. Os convidados podem navegar pelas bebidas e fazer pedidos. Mas ainda é apenas um cardápio digital.
Aqui é onde a IA entra. O ponto principal deste pequeno projeto era que eu não deveria ser o cardápio. Eu queria um cardápio digital, mas também um Assistente de Coquetéis de IA que pudesse recomendar bebidas em vez de eu fazer isso. Eu precisava construir algo que entenda preferências, recomende bebidas, mas apenas sugira bebidas que eu realmente posso preparar.
Essa última parte veio com vários desafios; levei alguns dias extras para conseguir as coisas do jeito que eu queria. Na primeira vez que testei o chatbot, ele recomendou um "Mojito", mas eu não tinha "Mojito" no cardápio. A IA sugeriu boas bebidas, mas não verificou se era possível misturá-las. Aprendi que construir agentes de IA não é apenas conectar a um modelo de linguagem. É sobre controlar o que o modelo pode e não pode dizer.
O código-fonte completo deste projeto está disponível no GitHub.
Vamos construir o bartender de IA.
O Bartender em Ação
Antes de mergulhar nos detalhes técnicos, deixe-me mostrar o que estamos construindo. Esta é a interface de chat real que os convidados podem usar.
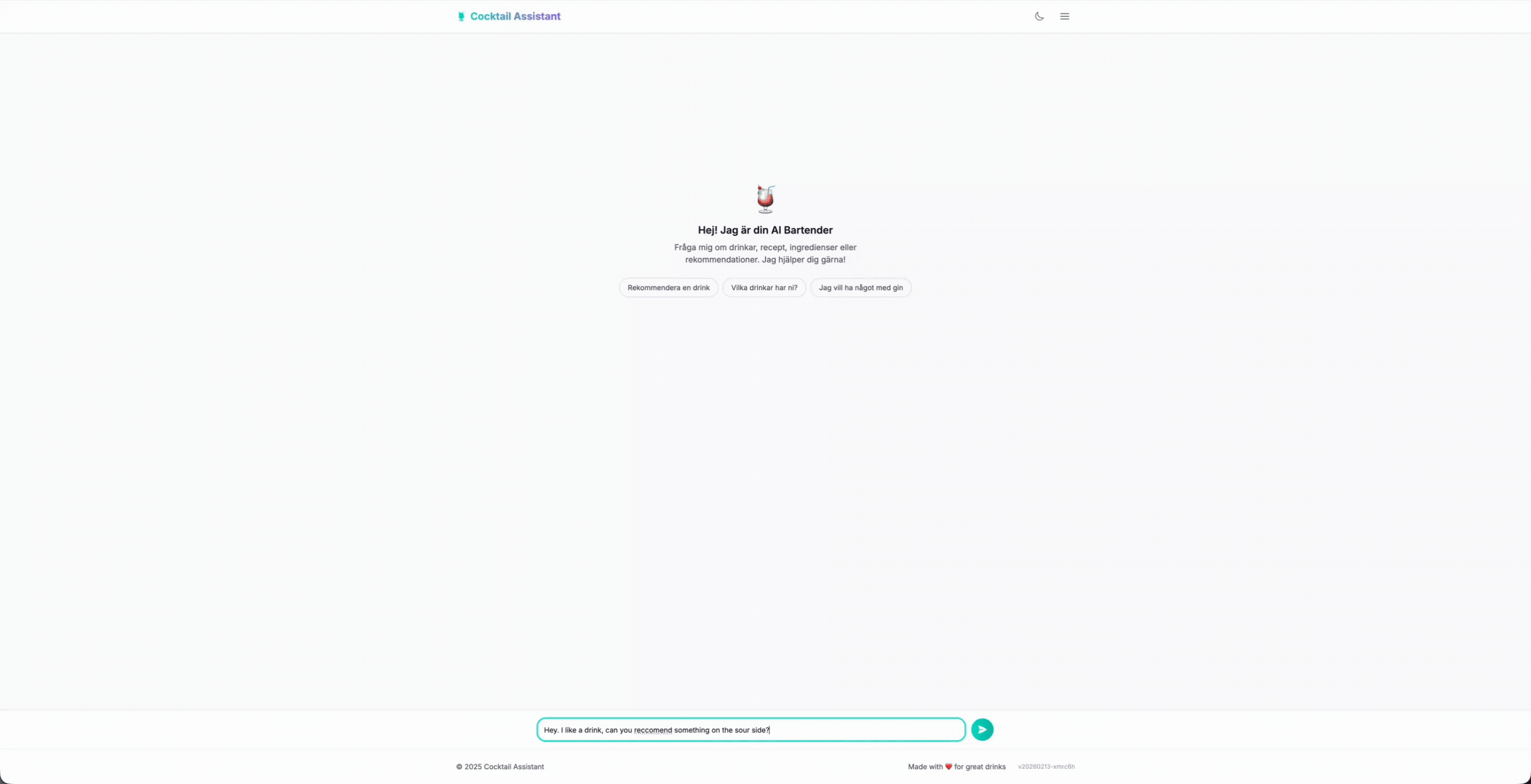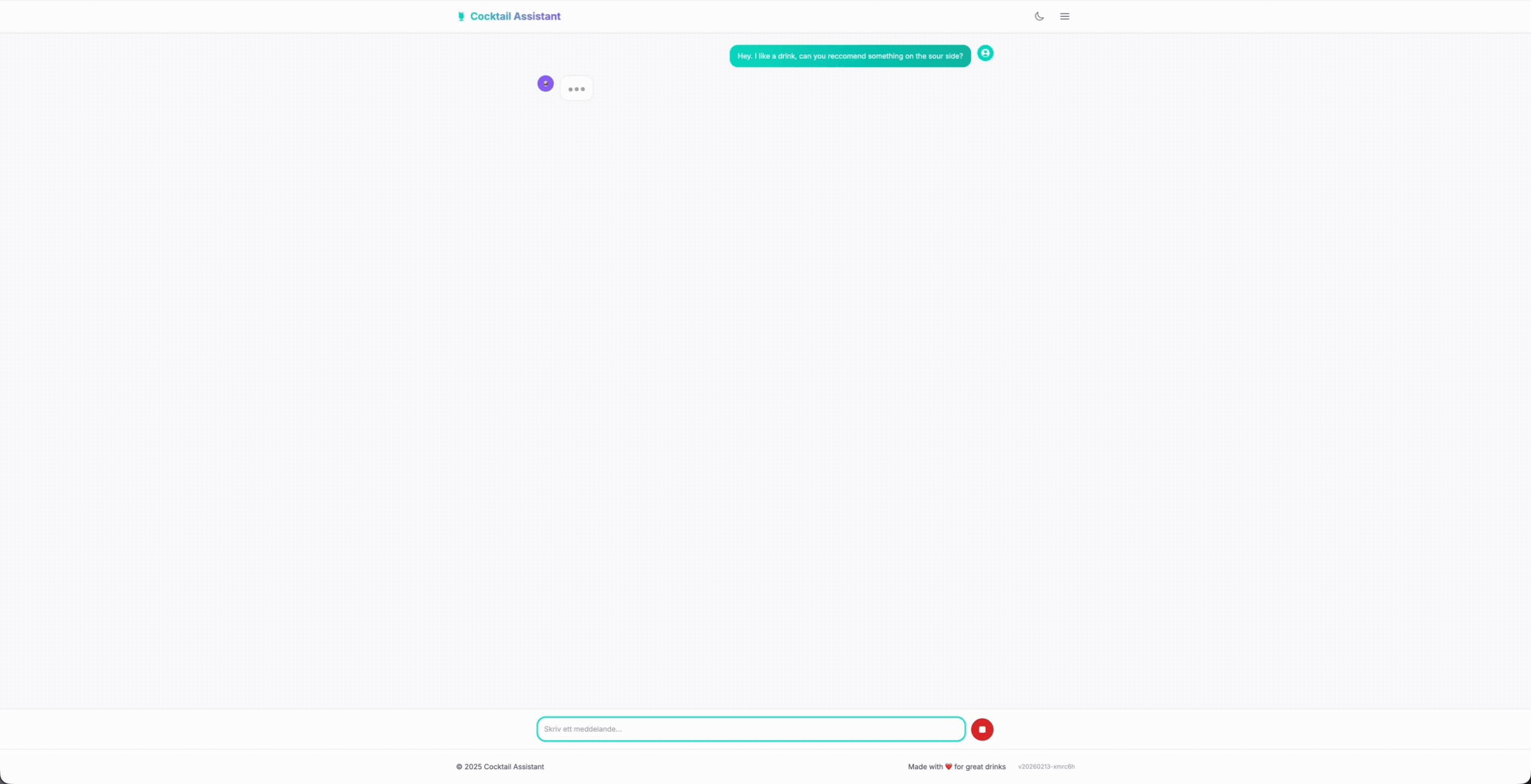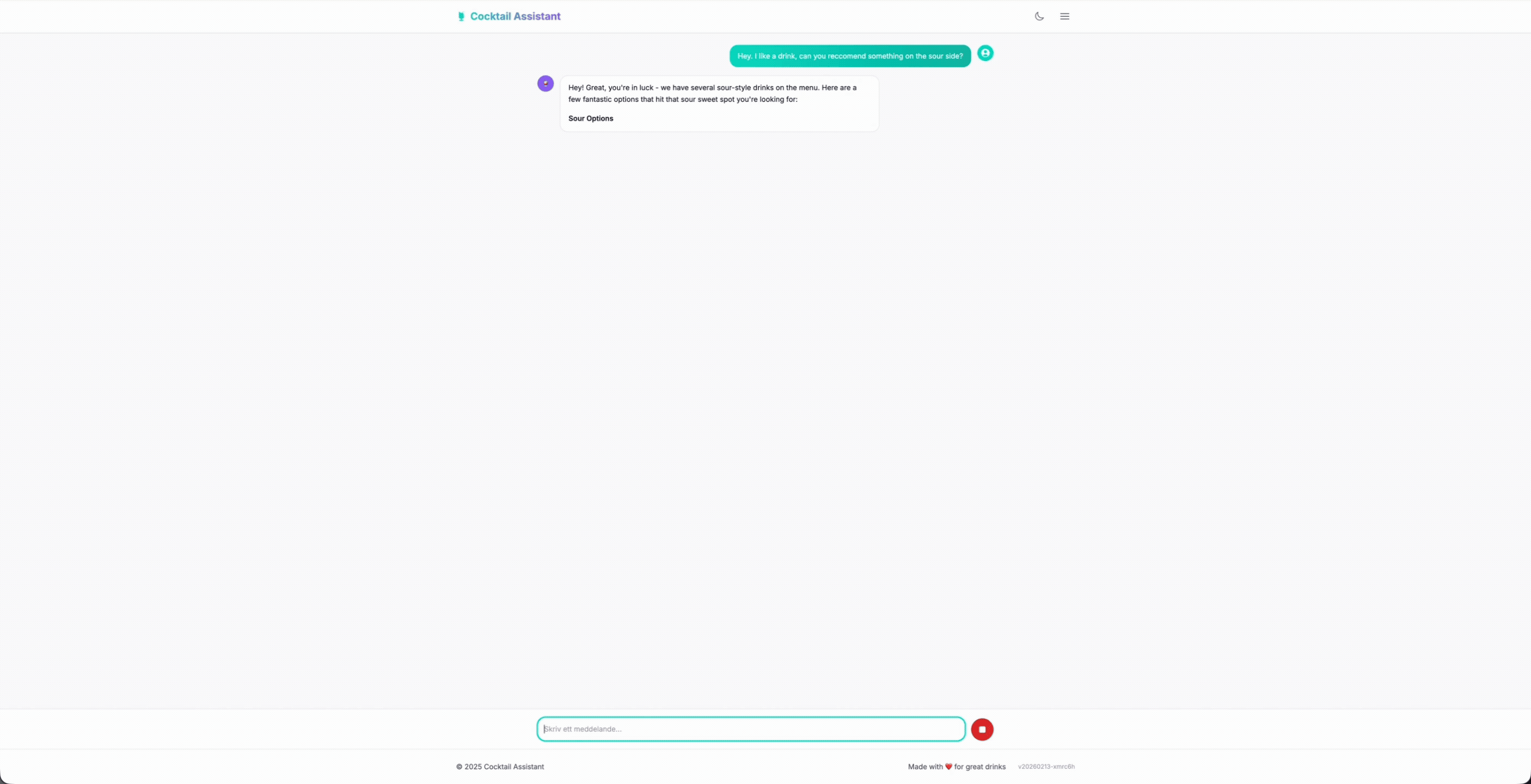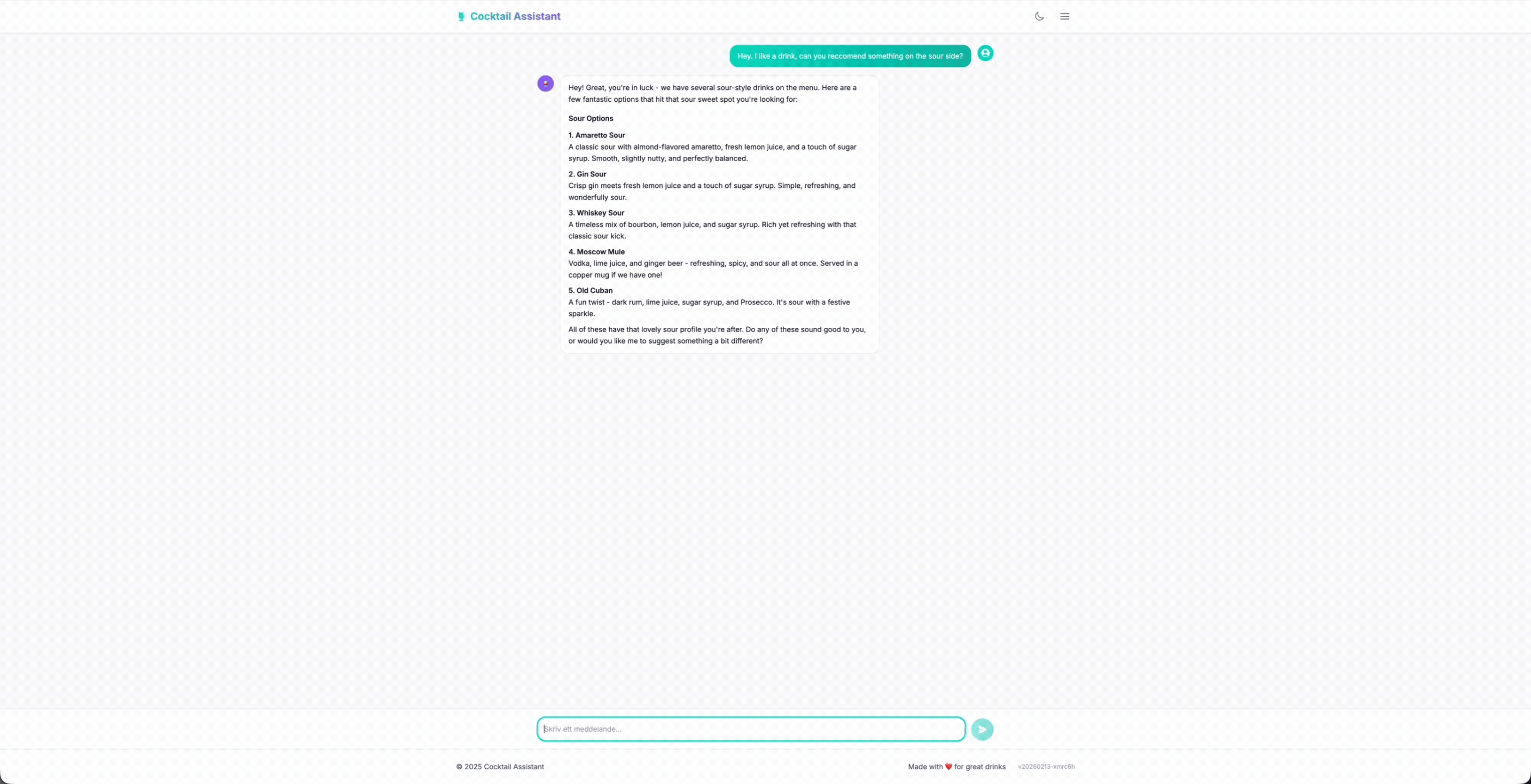
O fluxo de conversa é natural; o usuário pede bebidas, adiciona suas preferências como doce, azedo, amargo e assim por diante. O bartender responde, busca o cardápio e recomenda bebidas que realmente existem. Quando alguém pede algo que não temos, ele redireciona educadamente em vez de inventar coisas.
O que você não vê é tudo o que está acontecendo por trás dessa interface. O agente chama minhas ferramentas MCP para buscar o cardápio, carrega o histórico da conversa do AgentCore Memory, transmite a resposta palavra por palavra através do Lambda Web Adapter e segue regras rigorosas para evitar alucinações. Tudo invisível para o convidado. Tudo fazendo com que a experiência pareça como falar com um bartender real.
Visão geral da arquitetura
Vamos dar uma olhada na arquitetura e nos serviços que usaremos para construir o chatbot de IA Bartender.
Eu tenho o frontend em React chamando o AWS Api Gateway; isso é criado e configurado com resposta de streaming. Para implementar a lógica, é claro, eu recorro ao Lambda, que é configurado como integração com a API. Para lidar com o loop agente de uma maneira fácil, os Strands Agents vêm ao resgate. Nossa função Lambda, com Strands, então interage com o Amazon Bedrock e usa o Amazon Nova 2 Lite como LLM. O Amazon AgentCore fornece algumas partes muito importantes: memória para manter a conversa e gateway para alcançar minhas ferramentas MCP. Isso cria uma solução estável, econômica e sem servidor!

API de Chat com Streaming
A primeira coisa que eu precisava era criar um ponto de extremidade de API para o chat. Já temos um API Gateway da Parte 1 e 2 que lida com todos os endpoints REST: navegando por bebidas, gerenciando o cardápio, fazendo pedidos. Meu primeiro instinto foi simplesmente expandir essa API e adicionar uma rota /chat lá. Isso realmente não funcionou do jeito que eu queria.
A API principal usa a propriedade Events do SAM nas funções Lambda para definir endpoints. Normalmente é assim que eu configuro, mesmo que tenha algumas falhas. É muito simples para padrões de solicitação-resposta padrão, mas não para isso. Mas eu precisava de streaming de resposta para o chat, e os Eventos SAM não suportam responseTransferMode no momento. Simplesmente não havia como configurá-lo pela maneira normal.
Para fazer isso funcionar, tive que usar uma especificação OpenAPI e definir o responseTransferMode para STREAM, já que não seria possível manter a API atual e apenas adicionar especificação OpenAPI para o novo endpoint; a solução tornou-se uma pilha dedicada para a API de chat. Então eu criei um AWS::Serverless::Api separado com um DefinitionBody OpenAPI. Um benefício que vem com isso é que eu desacoplo as APIs; posso implantar a API de cardápio baseada em REST e a API de Chat de IA separadamente. Mudanças no chat não arriscam quebrar o fluxo de pedidos e vice-versa.
paths:
/chat:
post:
x-amazon-apigateway-integration:
type: aws_proxy
httpMethod: POST
responseTransferMode: "STREAM"
uri:
Fn::Sub: >-
arn:aws:apigateway:${AWS::Region}:lambda:path/2021-11-15/functions/${ChatStreamingFunction.Arn}/response-streaming-invocationsPrimeiro, como já mencionado, responseTransferMode: "STREAM" diz ao API Gateway para transmitir a resposta em vez de bufferizá-la. Em segundo lugar, o caminho URI usa /response-streaming-invocations em vez do normal /invocations. Esta é uma API de invocação Lambda diferente que suporta transferência em blocos. Sem esses dois, o API Gateway esperaria a resposta completa do Lambda antes de enviar algo ao cliente.
Streaming de Resposta
Por que passar por todo esse trabalho e pular todos esses obstáculos apenas para streaming? Porque a diferença na experiência do usuário é enorme.
A primeira versão que eu construí do chat era síncrona; era mais fácil assim. O Lambda esperava a resposta completa do Bedrock, depois retornava tudo de uma vez. Mas não fluía naturalmente; todos hoje estão acostumados a respostas chegando em fluxos. ChatGPT, Claude, Gemini e basicamente todos os chats de IA são construídos dessa maneira.
Com o streaming, o usuário vê a primeira palavra em milissegundos em vez de esperar segundos pela resposta completa. O resto flui palavra por palavra; no final, o tempo total é mais ou menos o mesmo, mas parece muito mais suave e, como humanos, nós o experimentamos como mais natural.
O termo técnico para tudo isso é "tempo até o primeiro token" versus "tempo até o último token". Para respostas bufferizadas, ambos são os mesmos. Para streaming, o tempo até o primeiro token é tipicamente inferior a um segundo. Esse primeiro token é o que importa!
Há também um benefício prático. Se o modelo começar a gerar bobagens ou ficar preso em um loop, o usuário vê imediatamente e pode cancelar.
Lambda Web Adapter para Streaming em Python
Agora, há uma pegadinha nisso tudo. O Python Lambda não suporta nativamente o streaming de resposta. Apenas o Node.js tem suporte integrado a streaming através da API de streaming de resposta do Lambda. Mas eu queria construir o agente em Python porque Python é minha linguagem preferida, e como todo o resto no backend é baseado em Python, eu queria tentar manter assim.
A solução aqui é usar o Lambda Web Adapter. É uma camada Lambda publicada pela AWS que envolve seu framework web—no meu caso, FastAPI—e traduz entre a API de invocação de streaming do Lambda e respostas HTTP padrão. Você escreve um aplicativo FastAPI normal com StreamingResponse, e o adaptador cuida do resto.
ChatStreamingFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/chat-streaming/
Handler: run.sh
Runtime: python3.13
Architectures:
- arm64
Timeout: 120
MemorySize: 1024
Layers:
# Lambda Web Adapter layer publicado pela AWS
- !Sub arn:aws:lambda:${AWS::Region}:753240598075:layer:LambdaAdapterLayerArm64:25
Environment:
Variables:
AWS_LAMBDA_EXEC_WRAPPER: /opt/bootstrap
PORT: 8080
AWS_LWA_INVOKE_MODE: RESPONSE_STREAMHá três variáveis de ambiente que fazem isso funcionar no final. AWS_LAMBDA_EXEC_WRAPPER diz ao Lambda para usar o adaptador como ponto de entrada em vez de chamar seu manipulador diretamente. PORT diz ao adaptador onde seu aplicativo FastAPI está ouvindo. E AWS_LWA_INVOKE_MODE definido como RESPONSE_STREAM habilita a codificação de transferência em blocos que torna o streaming possível.
O manipulador Lambda é apenas um pequeno script shell de duas linhas que iniciará o servidor FastAPI.
#!/bin/bash
exec python handler.pyO adaptador interceptará as solicitações da API de streaming do Lambda, as encaminhará para o FastAPI via HTTP na porta 8080 e, em seguida, transmitirá a resposta de volta bloco por bloco. Da perspectiva do meu código, estou apenas escrevendo um aplicativo FastAPI normal. A parte de streaming é totalmente tratada pela camada.
Então, no final, isso se torna uma solução bastante suave. Você pode encontrar a solução em Serverless Land também.
Dentro do Chat Lambda
Com a API e o streaming em lugar, vamos dar uma olhada no que realmente roda dentro da função Lambda.
Strands Agents
Ao construir um agente de IA do zero, temos que implementar muitas coisas: enviar a mensagem do usuário para o modelo, verificar se o modelo quer chamar uma de nossas ferramentas, chamar a ferramenta, enviar o resultado de volta para o LLM, verificar novamente e continuar loopando até que o modelo tenha uma resposta final. Basicamente, precisamos implementar o que é frequentemente referido como o Loop Agente. Depois, adicione streaming, recuperação de erros e estado de conversa no topo.
Strands Agents é um SDK de código aberto da AWS para nos ajudar a implementar o Loop Agente. Ele nos ajuda a reduzir o tempo de implementação de semanas para dias. Ele executará o loop agente para nós. Quando o modelo decidir que precisa verificar o cardápio, Strands invoca a chamada da ferramenta, alimenta o resultado de volta e continua até que o modelo esteja satisfeito e tenha uma resposta completa. Ele também se integra diretamente com o AgentCore Memory para gerenciamento de sessão e suporta streaming assíncrono.
A configuração básica é surpreendentemente fácil.
from strands import Agent
from strands.models.bedrock import BedrockModel
model = BedrockModel(model_id="amazon.nova-2-lite-v1:0")
agent = Agent(model=model, system_prompt="Você é um bartender.")
for chunk in agent.stream("Sugira uma bebida de gin"):
print(chunk, end="")Três linhas e você tem um agente de IA com streaming. Strands possui o loop; eu possuo a lógica de negócios.
Amazon Bedrock Nova 2
Para o LLM, optei pelo Amazon Nova 2 Lite. Por que o Nova 2 especificamente? Eu queria um modelo rápido; recomendar coquetéis e bebidas não é uma tarefa muito complexa, então um modelo menor e mais rápido deveria ser capaz de executar o trabalho bem. O tempo de resposta importa, e um modelo menor é mais rápido.
Desde o início, meu pensamento era usar o Nova Pro e o Nova Lite com o Amazon Bedrock Intelligent Prompt Routing para alternar entre os modelos dependendo da complexidade da entrada do usuário. No entanto, por algum motivo, o Nova Pro teve um pouco de dificuldade no uso da ferramenta, e para ser honesto, usar um modelo profissional para isso é um completo desperdício. Então, no final, eu simplesmente abandonei essa ideia.
O modelo Nova 2 Lite é um grande passo à frente da primeira geração do Nova. O modelo é rápido, barato e segue instruções muito bem. Mais importante, ele chama ferramentas de forma confiável e não alucina tanto quando você lhe dá restrições rigorosas.
AgentCore Memory
Como todos sabemos, as funções Lambda são sem estado; cada invocação começa do zero. Em uma conversa com várias voltas, isso não funciona. Se eu pedir "Eu gosto de gin" e depois "o que você recomenda?", a segunda invocação Lambda não tem ideia de que você mencionou gin na primeira interação. Claro, poderíamos armazenar coisas na memória Lambda, mas em um sistema multi-usuário isso não vai funcionar. Não tenho certeza em qual instância do tempo de execução Lambda minha interação vai parar. Precisamos de memória externa.
O AgentCore Memory resolve isso armazenando o histórico da conversa em um local central; todas as invocações Lambda podem ler dessa memória para ter a conversa atualizada. Cada usuário que interage com a IA obtém uma sessão, e a memória persiste entre invocações com base nesse ID de sessão. Quando o agente recebe uma nova mensagem, ele carrega o histórico da conversa da memória, processa a mensagem com contexto completo e salva o histórico atualizado de volta.
BartenderMemory:
Type: AWS::BedrockAgentCore::Memory
Properties:
Name: drink_assistant_bartender_memory
EventExpiryDuration: 30 # Dias para manter os eventos de conversa
MemoryStrategies:
- UserPreferenceMemoryStrategy:
Name: DrinkPreferences
Description: Extrai preferências de bebida do usuário
Namespaces:
- preferences/{actorId}O UserPreferenceMemoryStrategy torna as coisas interessantes. Ele extrai insights das conversas; se um usuário disser "Eu prefiro gin" várias vezes em sessões, a memória aprende isso e o torna disponível para futuras conversas. A memória de curto prazo armazena os eventos brutos da conversa, e a memória de longo prazo armazena os padrões extraídos.
No Chat Lambda, eu configurei o gerenciador de sessão Strands para usar a memória—uma configuração muito limpa e fácil.
from bedrock_agentcore.memory.integrations.strands.session_manager import (
AgentCoreMemorySessionManager
)
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=AgentCoreMemoryConfig(
memory_id=MEMORY_ID, session_id=session_id, actor_id=actor_id
),
region_name=REGION,
)O Agente Sem Ferramentas
Neste ponto, eu tenho um agente básico funcionando. Ele pode dar recomendações sobre bebidas via o Nova 2 LLM.
model = BedrockModel(
model_id="global.amazon.nova-2-lite-v1:0",
region_name=REGION,
)
session_manager = create_session_manager(session_id, actor_id)
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
session_manager=session_manager,
)Este agente pode conversar e interagir com o usuário; ele pode lembrar o contexto entre mensagens. Ele soará como um bartender, mas está faltando uma coisa importante que mencionamos no início. Ele não tem acesso ao cardápio real de bebidas; se pedirmos uma recomendação, ele sugerirá qualquer bebida que o LLM venha a mente. Ele sugerirá um coquetel à base de tequila mesmo se eu não tiver nenhuma tequila. Ele com certeza sugerirá um Mojito, um Cosmopolitan ou qualquer outro coquetel incrível que existir. Ele não sabe o que eu realmente posso preparar; isso é o que eu preciso resolver a seguir.
MCP Fornecendo Acesso ao Agente aos Dados
Nosso LLM no Nova certamente conhece milhares de coquetéis, como já mencionamos. Mas eu só quero que ele sugira as bebidas do cardápio. Eu poderia, é claro, fornecer o cardápio inteiro no prompt de sistema, mas isso não escalaria conforme o cardápio cresce, e se eu quisesse que ele sugerisse coisas fora do cardápio contanto que eu tivesse os ingredientes, bem, então isso não funcionaria; não seria prático.
A solução, claro, está no MCP, Protocolo de Contexto de Modelo. É um padrão para fornecer ao LLM ferramentas para usar—ferramentas que podem buscar dados, como o cardápio, por exemplo. Então o modelo decide durante a conversa que precisa de informações do cardápio, chama uma ferramenta, obtém os dados de volta e os usa na resposta.
O fluxo funciona mais ou menos assim: Um usuário pergunta "quais bebidas de gin você tem?" O agente reconhecerá que precisa do cardápio para responder a essa pergunta. Ele faz uma chamada de ferramenta para, neste caso, getDrinks. A ferramenta, implementada em uma função Lambda, consulta o banco de dados e retorna a lista de bebidas. Agora, o agente recebe essa lista e recomenda apenas bebidas que realmente estão no cardápio.
No momento, eu só implementei a ferramenta getDrinks, mas a arquitetura é flexível, e construir ferramentas adicionais é fácil. Por exemplo, uma ferramenta getIngredients que retorna o que tenho em estoque, uma ferramenta getPopular que classifica bebidas por contagem de pedidos, uma ferramenta orderDrink para fazer um pedido. Cada ferramenta é apenas outra função Lambda atrás do AgentCore Gateway; o agente fica mais inteligente sem o prompt de sistema ficar mais longo.
Implementando MCP com AgentCore Gateway
O AgentCore Gateway facilita o alojamento e fornecimento de ferramentas para o LLM. Ele suporta vários tipos de destino: Esquema OpenAPI, Lambda e outros servidores MCP externos. Quando comecei a construir a ferramenta, meu primeiro plano era usar o Esquema OpenAPI e apontá-lo para a API REST existente—apenas reutilizar o que eu já tinha construído. Faz sentido, certo?
Errado! Eu encontrei alguns problemas e preocupações que me fizeram repensar isso.
Mudando para Alvos Lambda do OpenAPI
O primeiro obstáculo que encontrei foi uma lacuna no suporte do CloudFormation. Os alvos OpenAPI exigem um provedor de credenciais de chave de API para autenticação; o Gateway precisa de credenciais para chamar minha API em meu nome. E aqui está o problema: o CloudFormation não tem um recurso nativo para ApiKeyCredentialProvider. Eu teria que criá-lo manualmente através do console ou usar um Recurso Personalizado apoiado por Lambda. Eu não sou um grande fã de Recursos Personalizados pois eles adicionam complexidade operacional. Para uma credencial que basicamente é definida e esquecida, essa sobrecarga não vale a pena.
O segundo problema acabou sendo ainda mais importante: acoplamento de contrato. A API atual foi construída para servir conteúdo ao meu webapp; ela retornava o que a interface do usuário precisava para renderizar. A ferramenta MCP certamente tem requisitos diferentes; por exemplo, ela não precisa da URL da imagem—simplesmente não faz sentido.
Para o Agente de IA, uma resposta JSON plana e compacta seria a mais otimizada. Na maioria dos casos, eu poderia até retornar apenas o nome da bebida; o LLM sabe o que é um "Gin & Tonic" ou "Moscow Mule". É apenas para minhas bebidas personalizadas que eu posso precisar retornar mais informações para o modelo.
Então eu tive algumas escolhas aqui: ou eu implemento o padrão de arquitetura "Backend For Frontend" e crio um BFF para cada cliente na frente da API REST, ou eu mudo totalmente e apenas crio um alvo Lambda para o AgentCore Gateway. No final, optei pela segunda abordagem.
# Resposta da Ferramenta MCP (otimizada para o agente)
{
"drinks": [
{"name": "Negroni", "ingredients": "gin, Campari, vermouth doce"},
{"name": "Gin & Tonic", "ingredients": "gin, água tônica, limão"}
],
"count": 2
}
# vs Resposta da API REST (otimizada para frontend)
{
"items": [...objetos completos de bebida com IDs, imagens, seções...],
"pagination": {"page": 1, "total": 50, "hasMore": true},
"meta": {"cached": true, "timestamp": "..."}
}O benefício dessa abordagem é que a API e a ferramenta MCP podem evoluir independentemente. Quando eu adiciono novos campos à API REST para recursos do frontend, o agente não é afetado. Criando um desacoplamento claro.
A Ferramenta getDrinks
Para implementar a ferramenta getDrinks, a função Lambda se conecta ao nosso banco de dados DSQL e busca a lista de bebidas. Não vou entrar em como essa conexão funciona; consulte a Parte 1 para detalhes sobre isso.
def handler(event, context):
"""Manipulador da ferramenta MCP, chamado pelo AgentCore Gateway."""
section_id = event.get("section_id")
rows = get_drinks_from_db(section_id)
# Retorna formato compacto para o modelo
drinks = [
{"name": row["name"], "ingredients": ", ".join(row["ingredients"])}
for row in rows
]
return {"drinks": drinks, "count": len(drinks)}O formato de resposta importa. Inicialmente, eu retornava detalhes completos da bebida, incluindo descrições, URLs de imagem e IDs. Não há sentido em fazer isso, e isso apenas consumiria tokens; reduzir isso aumenta a velocidade e é mais econômico.
Gateway CloudFormation
Para criar nosso AgentCore Gateway como normal, eu recorro ao CloudFormation, e a configuração não é muito direta.
BartenderGateway:
Type: AWS::BedrockAgentCore::Gateway
Properties:
Name: drink-assistant-bartender-gateway
ProtocolType: MCP
AuthorizerType: AWS_IAM
DrinksToolsTarget:
Type: AWS::BedrockAgentCore::GatewayTarget
Properties:
GatewayIdentifier: !Ref BartenderGateway
TargetConfiguration:
Mcp:
Lambda:
LambdaArn: !GetAtt McpToolsFunction.Arn
ToolSchema:
InlinePayload:
- Name: getDrinks
Description: >
Recupera coquetéis disponíveis do cardápio.
Retorna nomes de bebidas e ingredientes.O AgentCore Gateway usa autenticação IAM com um provedor de credencial GATEWAY_IAM_ROLE. A descrição da ferramenta é importante; ela diz ao modelo quando e como usar a ferramenta. Uma descrição curta e vaga leva o modelo a chamar a ferramenta em momentos errados ou não chamá-la quando deveria.
Adicionando MCP ao Agente
Agora que temos o MCP pronto para uso via AgentCore, precisamos fornecê-lo ao agente Strands para que ele possa chamá-lo.
from strands.tools.mcp import MCPClient
from mcp_proxy_for_aws.client import aws_iam_streamablehttp_client
mcp_client = MCPClient(
lambda: aws_iam_streamablehttp_client(GATEWAY_URL, "bedrock-agentcore")
)
tools = mcp_client.list_tools_sync()O MCPClient do Strands lida com o protocolo MCP, e mcp-proxy-for-aws adiciona autenticação IAM para chamar o AgentCore Gateway. Eu inicializo o cliente uma vez no início frio e cacho as ferramentas em um contexto global para que solicitações subsequentes pulem o configuração, para melhorar a velocidade das partidas quentes.
tools = get_mcp_tools()
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
session_manager=session_manager,
tools=tools,
)Com uma única linha adicionada, o agente agora pode chamar a ferramenta getDrinks quando precisar verificar o cardápio.
Criando o Prompt de Sistema
O prompt de sistema é o que guiará o LLM e definirá requisitos e estrutura. Lembre-se do problema do Mojito da introdução? É isso que vamos evitar com o prompt de sistema.
Primeiro rascunho
Meu primeiro prompt de sistema era muito simples e curto; ele fornecia muito pouca orientação.
Sistema: Você é um bartender útil. Quando os convidados pedirem recomendações de bebidas, use a ferramenta getDrinks para ver o que está disponível e faça sugestões com base em suas preferências.O resultado foi educado, mas não confiável.
Segunda rodada, adicionando restrições
Na segunda iteração, adicionei algumas restrições e guardrails explícitos.
Sistema: Você é um bartender. Use a ferramenta getDrinks para ver quais bebidas estão disponíveis. Recomende apenas bebidas que aparecem na resposta da ferramenta. Não sugira bebidas que não estejam no cardápio.Melhor, mas ainda não fornecia o que eu queria.
Terceira iteração
Agora comecei a adicionar algumas regras claras.
Sistema: Você é um bartender em um bar de coquetéis nórdico.
REGRAS:
- SEMPRE chame getDrinks antes de fazer recomendações
- Recomende SOMENTE bebidas que existem na resposta getDrinks
- Se uma bebida não estiver na resposta, diga "Desculpe, não temos isso no cardápio"
- Não descreva receitas ou ingredientes a menos que venham da ferramenta
Use linguagem descritiva (fresco, equilibrado, cítrico) ao discutir bebidas.Isso foi muito melhor; o LLM parou de sugerir bebidas que não estavam no cardápio. Mas quando os convidados faziam perguntas vagas como "surpreenda-me" ou "o que é popular?", o LLM às vezes pulava a chamada da ferramenta e recomendava bebidas que conhecia; a palavra-chave "SEMPRE" não era sempre suficiente.
Iteração final
No final, criei um prompt de sistema longo, na verdade com ajuda de IA. Usar IA para criar prompts para IA é na verdade uma abordagem muito boa e cria resultados muito bons.
SYSTEM_PROMPT = """# AGENTE BARTENDER
## REGRAS CRÍTICAS - LEIA PRIMEIRO
**NUNCA DEVE:**
- Sugerir bebidas que NÃO estão no resultado getDrinks
- Inventar ingredientes ou bebidas que não existem no cardápio
- Recomendar uma bebida sem primeiro chamar getDrinks
**SE UMA BEBIDA NÃO ESTIVER NO CARDÁPIO:**
Diga SOMENTE: "Desculpe, não temos isso no cardápio. Posso sugerir algo else?"
**REGRA DE LINGUAGEM:**
- Detecte o idioma do usuário e responda no mesmo idioma
- Se o usuário escrever em sueco, responda em sueco
---
## FERRAMENTAS
### getDrinks
Busca bebidas do nosso cardápio.
- SEMPRE chame esta ferramenta quando o convidado pedir recomendações
- Esta é sua ÚNICA fonte de informações sobre bebidas
- Recomende SOMENTE bebidas que existem na resposta
## IDENTIDADE
...
## FLUXO DE CONVERSA
...
## LIMITAÇÕES
...
"""Colocar "REGRAS CRÍTICAS - LEIA PRIMEIRO" no topo com formatação em negrito sinaliza importância; "NUNCA DEVE" é mais forte do que "não" ou "evite", e especificar exatamente o que dizer quando uma bebida não está disponível remove ambiguidade; o modelo não precisa descobrir como frasear uma rejeição.
Eu também adicionei a regra de detecção de idioma depois de perceber que o agente respondia em inglês mesmo quando eu pedia em sueco. Essas podem parecer pequenos detalhes, mas eles somam para uma melhor experiência.
Testes
Após cada iteração de prompt, eu executei os mesmos cenários de teste, para que pudesse rastrear as melhorias mais facilmente do que se apenas pedisse coisas aleatórias.
- Correspondência direta: "Eu quero um Negroni" (nós temos)
- Sem correspondência: "Posso pegar uma Piña Colada?" (nós não temos)
- Solicitação vaga: "Algo refrescante com gin"
- Desafio: "E um Mojito com melancia?" (testando se ele inventa variações)
- Fora do tópico: "Como está o tempo?" (deve permanecer no personagem)
O prompt final passou em todos os cinco testes com sucesso. Versões anteriores falhavam em alguns dos cenários.
Ao construir agentes de IA, o prompt de sistema é um de nossos principais controles. É importante sermos explícitos, repetitivos e colocar as regras mais importantes onde o modelo as vê primeiro.
O Loop Agente
Eu já mencionei o Loop Agente algumas vezes, mas o que é em detalhes? Como ele realmente funciona? Vou tentar explicar.
Um usuário começa pedindo ao agente uma pergunta ou dando uma ordem direta—algo como "Eu quero algo com gin" no frontend React. O frontend faz POST para o ponto de extremidade /chat. O API Gateway invoca o Lambda de streaming através do /response-streaming-invocations, e o Lambda Web Adapter inicia o FastAPI, que lida com a solicitação. O manipulador Lambda carrega ferramentas MCP, inicializa o agente Strands que iniciará tudo.
Strands começa enviando a mensagem do usuário para o LLM Nova 2 junto com o prompt de sistema que definimos anteriormente e qualquer histórico de conversa de mensagens anteriores, buscando-o do AgentCore Memory. O modelo lê o prompt de sistema, vê as regras críticas sobre sempre chamar getDrinks, e decide que precisa de dados do cardápio antes de poder recomendar qualquer coisa; isso faz com que ele faça uma chamada de ferramenta.
Strands pega o resultado da chamada da ferramenta e alimenta esse resultado de volta para o modelo.
Agora o modelo tem o cardápio real, faz um filtro para bebidas à base de gin, considera a outra preferência do convidado e cria uma recomendação. Cada token agora é transmitido através do Strands, através do StreamingResponse do FastAPI, através do API Gateway e para o frontend, e o AgentCore Memory salva a conversa para a próxima vez.
Aqui está o núcleo do ponto de extremidade de streaming.
async def stream_response():
agent = Agent(
model=model,
system_prompt=SYSTEM_PROMPT,
tools=get_mcp_tools(),
session_manager=create_session_manager(session_id, actor_id),
)
async for event in agent.stream_async(message):
if isinstance(event, dict) and event.get("data"):
yield f"data: {json.dumps({'chunk': event['data'], 'sessionId': session_id})}\n\n"
yield f"data: {json.dumps({'done': True, 'sessionId': session_id})}\n\n"
return StreamingResponse(stream_response(), media_type="text/event-stream")O método stream_async é onde o loop agente vive. Strands lida com o necessário voltar e forth entre o modelo e as ferramentas internamente. Da perspectiva do meu código, eu apenas itero sobre eventos e produz blocos de texto como Eventos Enviados ao Servidor. Strands decide quando o modelo precisa de outra chamada de ferramenta versus quando está pronto para responder.

Custo
Para uso doméstico ocasional, isso é essencialmente gratuito.
| Componente | Custo |
|---|---|
| Bedrock Nova 2 Lite | ~$0.001/1K entrada, ~$0.002/1K tokens de saída |
| Lambda | ~$0.0000166 por GB-segundo |
| AgentCore Memory | Incluído com Bedrock |
| AgentCore Gateway | Incluído com Bedrock |
| Aurora DSQL | Pague por solicitação, mínimo para tráfego baixo |
Uma conversa típica custa frações de centavo. Mesmo com um grupo de 20 pessoas fazendo perguntas toda a noite, o total seria inferior a um dólar.
E Agora?
O Bartender de IA agora está completo; todas as três partes estão concluídas.
Na Parte 1 eu abordei a base serverless com Aurora DSQL, APIs, autenticação e geração de imagem orientada a eventos. A Parte 2 adicionou registro de convidados com códigos de convite, JWTs autoassinados e atualizações de pedidos em tempo real com AppSync Events. Nesta Parte 3 final, construí o agente de chat de IA com Strands, ferramentas MCP, AgentCore Memory e streaming de resposta.
Ideias futuras incluem expandir as ferramentas, adicionando inventário de ingredientes, talvez de uma imagem. Apenas minha própria imaginação define os limites.
Palavras Finais
O que começou como uma solução para parar de ser o menu humano em uma festa em casa se transformou em um mergulho profundo em serverless, orientado a eventos e IA. Cada parte veio com seus próprios desafios e problemas que foram muito divertidos de resolver.
O código-fonte completo está disponível no GitHub.
Confira meus outros posts em jimmydqv.com e me siga no LinkedIn e X para mais conteúdo sobre serverless.
Agora Vá Construir!